
顔認証で人数カウント! Python から呼び出してみる
Face01_list は「通った人のユニーク数と顔画像ファイルを得るアプリケーション」です。
どの程度の性能か測るためにサンプル動画を用意してその動作をキャプチャし検証してみたいと思います。
今回は crop_speed 値を下げ、よりアプリケーションに負荷がかかる形で検証します。
こちらの記事は古くなっており非推奨となりました。
最新のドキュメントは以下から閲覧可能です。
・GitHub FACE01
・FACE01 document
サンプルスクリプト
まず、Face01_list の検証をするためにサンプルスクリプトから呼び出して結果を検証します。
#!/usr/bin/python3
# -*- coding:utf-8 -*-
print('Start test_script')
# Face01_list の呼び出し ================================================
import listDlib as l
from multiprocessing import Pool
kaoninshoDir, outputDIR = l.home()
pool = Pool(3)
crop_speed=30
pool.apply_async(l.faceCrop, (kaoninshoDir, crop_speed))
pool.apply_async(l.person_count, (outputDIR,))
l.openDIR(outputDIR, tolerance=0.63)処理全体をスムーズに行うため、マルチプロセスを採用しています。
今回の設定値は以下のようにしました。
- crop_speed
顔検出の頻度を調節する。値が小さいほど多くの顔を検出するがその分処理は遅くなるので調節する。デフォルトは 50
今回は 30 にしてより多くの顔画像を読み込むようにし、あえて負荷をかける。 - tolerance
同一人物を検出した場合にユニーク数に含めないように調節する。値が大きくなるほど似ている人をユニーク数に含める。
デフォルトは 0.54
今回は 0.63 にして緩めに設定してみる。
検証環境
検証環境: Python 3.6.9, Ubuntu 18.04.3 LTS, Linux 4.15.0-66-generic, AMD Ryzen 5 1400, MemTotal: 16421236 kB, GeForce GT 710
検証用サンプル

映画ターミネーターに出演しているアーノルド・シュワルツェネガー、リンダ・ハミルトン、そして通訳の方の3人が動画内で確認できます。
この動画サンプルを「test.mp4」として処理します。
検証処理中の様子
Linux 版で処理中の様子をキャプチャしました。
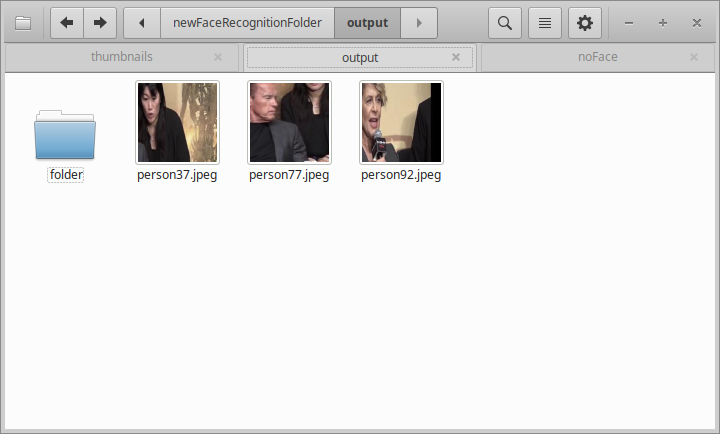
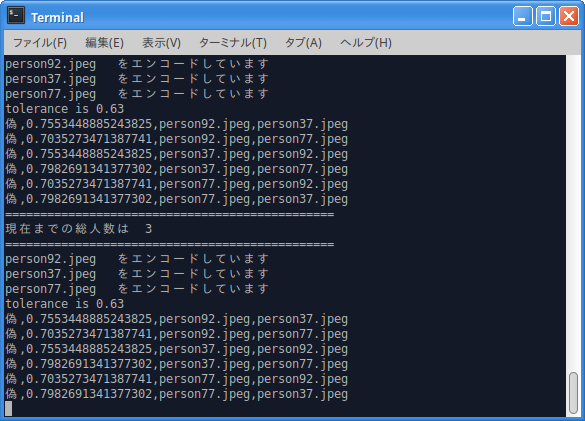
顔画像が順次検出され、それを元にエンコード処理を行い各顔画像ファイルがユニークな人物かを判定していきます。
マルチプロセスで動作しているので
- 顔画像の検出と保存処理
- 顔画像の 128 次元エンコード化と各々のエンコード値の比較処理
- その時その瞬間の総人数表示
を平行に処理しています。
この検証用動画では「3人」出演していますが、様々な表情・様々な顔の角度や仕草で多くの顔画像ファイルが発生していきます。
それらを 128 次元エンコード処理し、ユニークな人物かどうかを比較処理しています。
最終的に「3人分」の顔画像ファイルだけが残り、標準出力されています。
まとめ
今回は前回と異なり、日本人と外国人が混在する動画での検証を行ってみました。
この場合でも「3 人」ときちんと表示されることが分かりました。
以上です。
Face01_list は「その場所に現れた人のうち、そのユニークな人数と個別の顔画像ファイルを得る」にはもってこいのアプリケーションです。
是非ご活用ください。

