
[運用前に] MongoDBの概念を知る

対象読者
- MongoDBを採用することはもう決まっているが、まだ使ったことがない人
- MongoDBの概念が掴みきれてない人
- RDBの概念はなんとなく知っている人(使いこなせるわけではない)
注意点
- NoSQLの説明は行いません。
- MongoDBを採用することは決まっているので、RDBとの長所・短所の比較はしません。
- RDBと比較することによって、MongoDBの概念を理解することを目的としています。
- 用語を覚えることに力点をおいています。
- 様々な使い方(コマンドなど)は範囲外です。
- 初歩的な使い方は、記事最後のリンクを参照してください。
- MongoDBのインストール(プロジェクト単位のためDocker)について以下の記事で解説してます。
[Docker] プロジェクト専用のMongoDB環境を構築する
用語
まず用語を整理します。
スキーマ
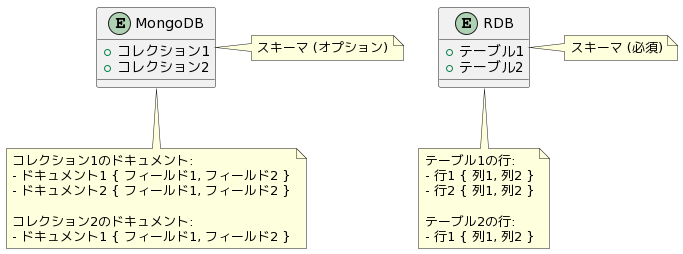
RDBでは必須ですが、MongoDBでは必須ではありません。
スキーマはデータベースの「構造」を定義するものであり、それには以下のような要素が含まれることが多いです。
- 型(Type): 各フィールドがどのようなデータ型(整数、文字列、日付など)を持つか。
- 関係性(Relationship): どのテーブルやコレクションがどのように関連しているか。例えば、一つの顧客が複数の注文を持つ場合など。
- 制約(Constraint): データが満たすべき条件。例えば、一意性、非NULL、参照整合性など。
- インデックス(Index): 検索性能を向上させるためのインデックス情報。
- ビュー(View): 複数のテーブルから必要な情報だけを組み合わせて新しいテーブルのように見せる仮想テーブル。
- トリガー(Trigger): 特定の操作(INSERT, UPDATE, DELETEなど)が行われたときに自動的に実行される処理。
スキーマとは、これらの要素を組み合わせて、データベースの「構造」を形成します。
コレクション
コレクションは、RDBのテーブルに相当するもので、ドキュメントが格納される場所です。一つのデータベース内に複数のコレクションを持つことができます。
コレクション名はそのコレクションが何を表しているのかを識別するためのものです。
コレクション名の注意点
- 一意性: 同じデータベース内でコレクション名は一意でなければなりません。
- 意味: 通常、コレクション名はその中に保存されるドキュメントの種類を表す名前が選ばれます。例えば、ユーザー情報を保存するコレクションなら
users、商品情報を保存するならproductsなど。 - ケースセンシティブ: MongoDBのコレクション名はケースセンシティブです。つまり、
usersとUsersは異なるコレクションとして扱われます。
例
users: ユーザー情報を保存するコレクションorders: 注文情報を保存するコレクションproducts: 商品情報を保存するコレクション
ドキュメント
ドキュメントは、MongoDBでデータを保存する基本的な単位です。
JSON形式に似ており(BSON)、フィールドと値のペアで構成されます。一つのコレクション内には、異なるスキーマ(フィールドの構造)を持つドキュメントを保存できます。
// ドキュメント1
{
"_id": ObjectId("5f50c31b8411a967a67218d8"),
"name": "Taro",
"email": "taro@example.com"
}
// ドキュメント2
{
"_id": ObjectId("5f50c31b8411a967a67218d9"),
"name": "Hanako",
"email": "hanako@example.com",
"age": 25
}
// ドキュメント3
{
"_id": ObjectId("5f50c31b8411a967a67218da"),
"name": "Jiro",
"phone": "090-xxxx-xxxx"
}ドキュメントの特性
- _idフィールド: MongoDBのドキュメントには自動的に
_idフィールドが追加され、一意の識別子(通常はObjectId)が割り当てられます。(後述) - スキーマレス: 同じコレクション内のドキュメントは、異なるフィールド、異なるデータ型を持つことができます。
- ネスト: ドキュメント内に他のドキュメント(サブドキュメント)や配列を持つことができます。
データ型
- MongoDBのドキュメントはBSON形式で保存されるため、JSONとは異なり、日付やバイナリデータなども保存できます。
サイズ制限
- 単一のドキュメントの最大サイズは16MBです。
更新操作
- ドキュメントは不変ではなく、後から更新や削除が可能です。
- 更新操作はフィールドレベルで行うことができます。
フィールド
ドキュメント内の各要素(キー)を指します。値としては数値、文字列、配列、エンベッデッドドキュメントなど多様なデータ型を持つことができます。
フィールド名の制限
- ドット(.)とドル記号($): フィールド名にはドット(.)やドル記号($)を含めることはできません。
- ケースセンシティブ: フィールド名はケースセンシティブです。つまり、
nameとNameは異なるフィールドとして扱われます。
データ型
- MongoDBは多様なデータ型をサポートしています。これには、整数、浮動小数点数、文字列、日付、配列、エンベッデッドドキュメント(サブドキュメント)などが含まれます。
インデックス
- フィールドにインデックスを作成することで、そのフィールドでの検索速度を向上させることができます。
更新操作
- フィールドレベルでの更新が可能です。つまり、ドキュメント全体を更新するのではなく、特定のフィールドだけを更新ができます。
配列とエンベッデッドドキュメント
- フィールドの値として配列やエンベッデッドドキュメント(他のドキュメントを含む)を持つことができます。これにより、関連するデータを一つのドキュメント内で管理ができます。
Null値
- フィールドは存在しない場合、または明示的に
nullが設定されている場合があります。これらは異なる状態であり、クエリで区別されます。
_idフィールド
_idフィールドはMongoDBのドキュメントに自動的に追加されるフィールドで、ドキュメントの一意な識別子として機能します。以下にその主な特性と用途について説明します。
idフィールドの特性
- 一意性: 同じコレクション内で
_idフィールドの値は一意でなければなりません。 - 不変性: 一度設定された
_idは変更することができません。 - 自動生成: ドキュメントを作成する際に
_idフィールドが指定されていない場合、MongoDBが自動的にこのフィールドを追加し、一意の値(通常はObjectId)を生成します。
データ型
- 通常、
_idフィールドはObjectIdという12バイトのデータ型で生成されますが、必要に応じて他のデータ型(数値、文字列など)を使用することもできます。
ObjectIdの構造
- ObjectIdは12バイトで構成されており、生成時刻、マシンID、プロセスID、カウンタなどから生成されます。
- この構造により、ObjectIdはほぼ一意であり、生成時刻を知ることもできます。
インデックス
_idフィールドには自動的に一意のインデックスが作成されます。これにより、_idフィールドを用いた検索が高速に行えます。
用途
- ドキュメントの一意な識別子として使われるため、データの参照や更新、削除などで頻繁に使用されます。
その他の用語
運用時に必要になる用語を整理します。
クエリ
- MongoDBには独自のクエリ言語があります。
- SQLとは異なり、JSON形式でクエリを記述します。
アグリゲーション
- 複数のドキュメントに対して操作を行い、計算結果を得るためのフレームワークです。
- グループ化、ソート、フィルタリングなどが可能です。
シャーディング
- 大量のデータを扱う場合、シャーディングを用いてデータを分散させることができます。
- これにより、水平方向にスケーリングすることが可能です。
レプリケーション
- データの可用性を高めるために、レプリケーション(複製)が用いられます。
- 主ノードと複数の従属ノードがあり、主ノードがダウンした場合には従属ノードが主ノードの役割を担います。
トランザクション
- MongoDB 4.0以降では、マルチドキュメントトランザクションがサポートされています。
- これにより、複数のドキュメントにまたがる操作を一貫性を持って行うことができます。
概念
初学者向けに以下のような表が紹介されています。
この表には「厳密には異なる」と書いてあります。
| MongoDB | RDB |
|---|---|
| データベース | データベース |
| コレクション | テーブル |
| ドキュメント | 行(レコード) |
| フィールド | 列 |
もう少し説明を足した表が以下となります。(あまり違いません)
RDBにフィールドやドキュメントといった概念はありませんが、表の都合上、MongoDBの概念を当てはめています。
| 用語 | MongoDBの説明 | RDBの説明 |
|---|---|---|
| データベース | 複数のコレクションをまとめて管理する単位。 | 複数のテーブルをまとめて管理する単位。 |
| コレクション | ドキュメントが保存される場所。スキーマが固定されていない場合もある。 | 行と列で構成され、スキーマ(テーブルの構造)が固定されている。 |
| ドキュメント | データの基本単位。BSON(バイナリ形式)で保存される。 | テーブル内の一つのデータセット。各列に値が格納される。 |
| フィールド | ドキュメント内の各要素(キー)。多様なデータ型を持つことができる。 | テーブル内で同じデータ型の値が格納される場所。 |
| スキーマ | コレクションの構造を定義するもの。必須ではない。 | テーブルの構造を厳密に定義するもの。必須。 |
概念図
初歩的な操作
以下の記事を参照下さい。
【やってみよう】NoSQL「MongoDB」を10分で学べる記事
運用前の注意点
1. コレクションとフィールド設計
- コレクション名の選定: 何を格納するかによって、コレクション名を明確にします。例えば、
users、productsなど。 - フィールドのキーとデータ型: 各ドキュメントが持つフィールドのキー名とそのデータ型を決定します。例えば、
username: String、age: Numberなど。
とりあえず、これだけ抑えておけば大丈夫です。
2. クエリ最適化
- 頻繁にアクセスするフィールド: アプリケーションでよく使うフィールドには、インデックスを設定します。
- 読み書きのバランス: アプリケーションの読み(Read)と書き(Write)の頻度に応じて、インデックスやシャーディングを調整します。
3. トランザクションと整合性
- 必要なトランザクション: 複数のコレクションにまたがる操作がある場合、トランザクションをどう設計するかを考えます。
- 整合性の確保: 必要に応じて、ACID特性(原子性、一貫性、独立性、耐久性)をどう確保するかを計画します。
おわりに
MongoDBの用語と概念についてまとめました。
入り口としてお役に立てば幸いです。
以上です。ありがとうございました。

