顔データを正しく再登録する
こちらの記事は古くなっており非推奨となりました。
最新のドキュメントは以下から閲覧可能です。
・GitHub FACE01
・FACE01 document
認証の精度を上げるための施策は2つあります。
ひとつは対象となるカメラ映像を高解像度にすること。
もう一つは登録する顔データをしっかりとしたものにすることです。
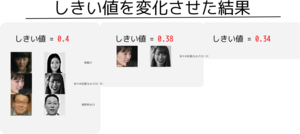
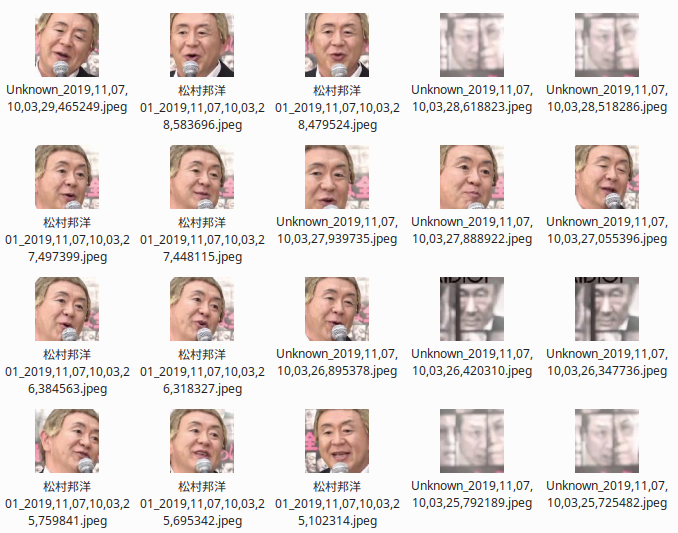
下の画像は、登録されていた顔写真から「いらないもの」として抜き出した写真です。

上の「捨てた顔写真」は
- 解像度が低い
- 同一人物ですでに似ている画像がある
- 正面を向いていない
- 修正が入った画像である
などの理由で顔写真フォルダから抜き出しました。もちろん npKnown.txt ( 128 次元顔データ配列 ) は抜いた後に作り直しました。
人物数 164 人に対して顔写真の数は 1506 個。この内捨てた顔画像 1113 個、残った顔画像が 393 個になりました。実に約 74% のいらない顔画像を捨てたことになります。
上の顔画像は、残った顔画像 393 個に対して更に次の修正を加えたものです。
$ mogrify -resize 100x100 ./*
$ mogrify -unsharp 12x6+0.5+0 ./*一行目は、各顔画像を 100×100 にリサイズしてあります。
二行目は、それぞれの顔画像に対してアンシャープマスクを適用しています。
こうすることによって 128 次元顔データがよりしっかりしたデータとなることを狙っています。



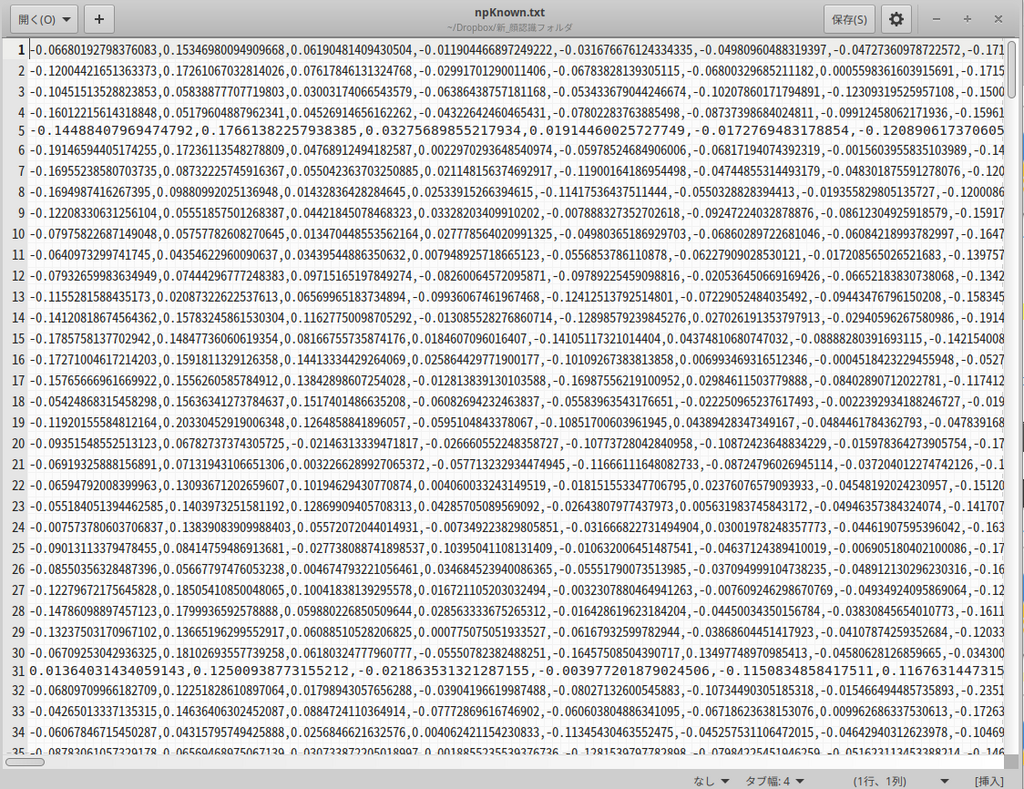
このようにして再作成した顔画像に対して test_script.py を走らせます。そうすると、npKnown.txt (右図)が自動的に作成されます。npKnown.txt には各顔画像に対しての 128 次元数値データ配列が書き込まれています。
この様にして整理した顔画像ファイルと顔データを使って、test_script.py を走らせた結果を以下に掲載します。
こちらの記事は古くなっており非推奨となりました。
最新のドキュメントは以下から閲覧可能です。
・GitHub FACE01
・FACE01 document
検証環境: test_script.py, Python 2.7.15+, Ubuntu 18.04.3 LTS, Linux 4.15.0-66-generic, AMD Ryzen 5 1400, MemTotal: 16421236 kB, GeForce GT 710
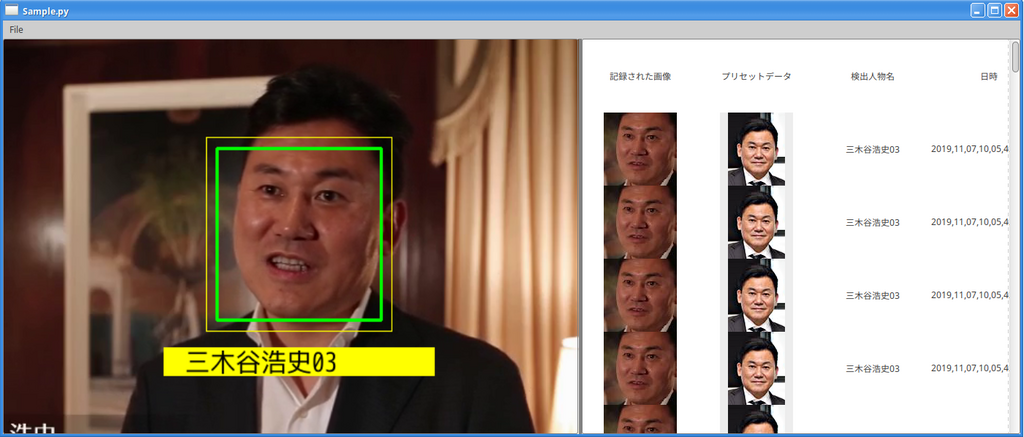

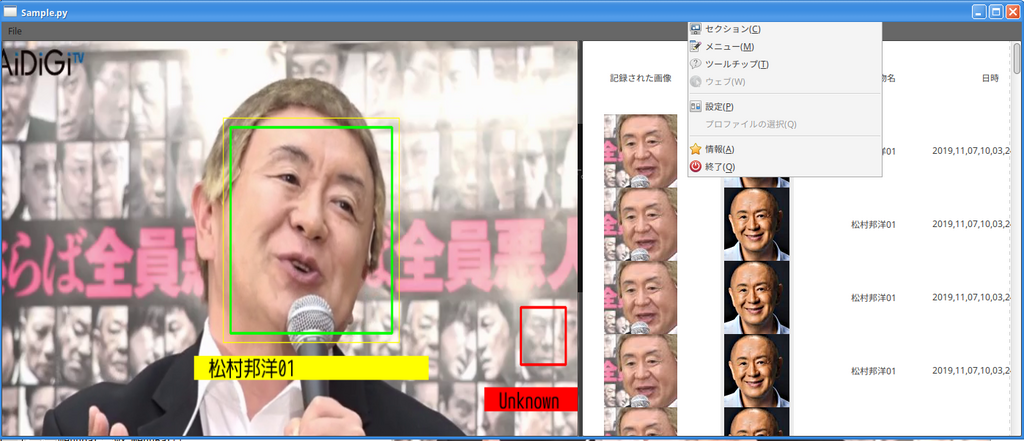
体感で良くなっていることを実感できました。
顔データの登録はこの様なルールを先に決めておくのが重要です。例えば、先の mogrify コマンドはシェルスクリプトに記述しておいて同じディレクトリは一括処理を出来るようにしておくと便利です。