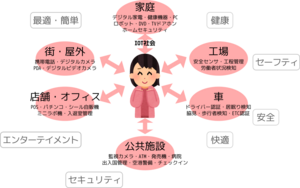
顔認証の処理の流れ
こちらの記事は古くなっており非推奨となりました。
最新のドキュメントは以下から閲覧可能です。
・GitHub FACE01
・FACE01 document

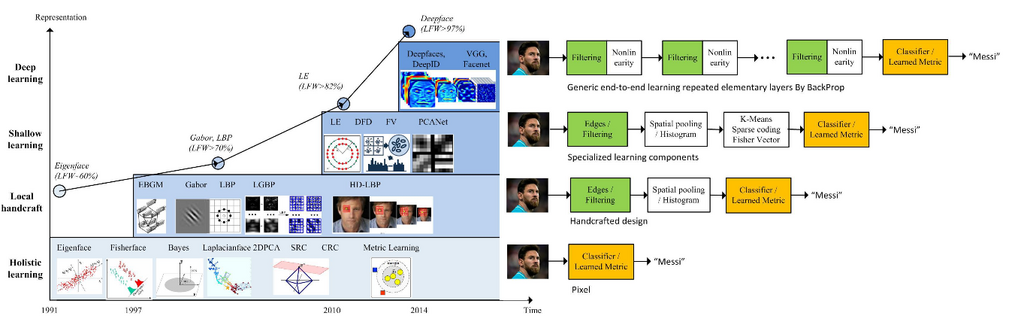
1991年に固有顔(Eigenface, 固有ベクトルの集合)[図1] が発表されて以来、顔認証はパターン認識・コンピュータビジョン関連の様々な研究者の間で盛んに研究されました。近年ではディープラーニング技術によって格段に精度が増し、人間の認知能力を超えるようになりました。
Face01 では [図2] のように動画の各フレームからアンシャープマスクなどの「前処理」を行い次に特徴点の抽出を行います。高速化のためにこれらの顔画像は縮小され、また numPy 配列へと変換されます。
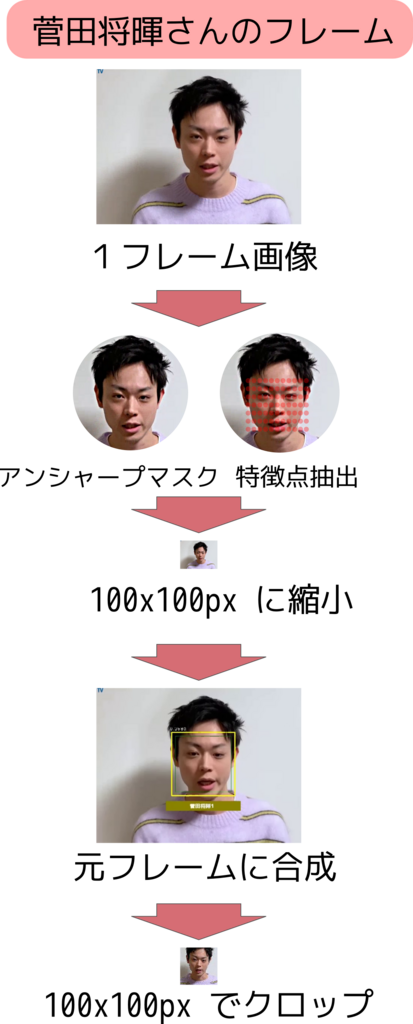
予め顔データの numPy 配列から近似の候補を絞り出し、閾値以下のファイル名を返り値として出力するようになっています。
この時プライバシーの観点から元画像を端末に残さないようにすることも可能です。その場合は numPy 配列だけになりますので人間への可読性は失われプライバシーに配慮した運用となります。
1.顔検出
高速な HOG 形式とより緻密な CNN 方式のどちらかを用いますが、Face01 は高速な HOG 、Face01_CNN は CNN を用いています
2.顔特徴点検出
顔領域内の目や口の端点など、基準となる特徴点を検出します。それにより正確に顔の特徴を取り出せるよう画像位置補正が可能になります
3.前処理
顔の位置や回転・向き、照明変化や眼鏡の影響など様々な変動要因を出来る限り排除します。Face01 はこの時アンシャープマスク処理をかけて、更に特徴点が際立つように処理をしています
4.特徴量抽出
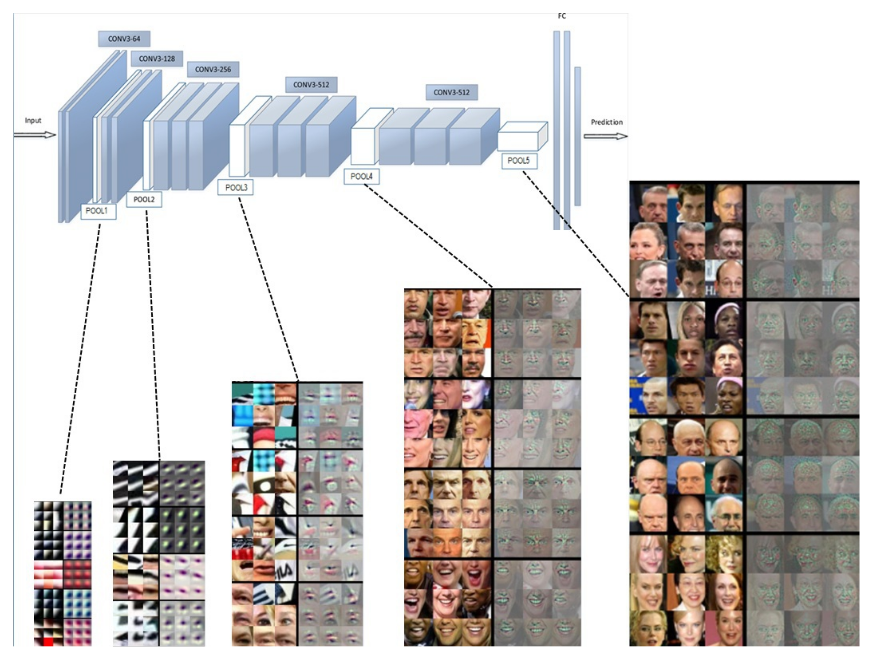
顔を見分けるための特徴を顔から抽出します。過去には様々な方法が試行錯誤されてきましたが [図3] 現代的なアルゴリズムでは [図4] が示すようにディープラーニングが主流となっています
神経細胞を模した処理単位を層状に積み重ねた構造をなしていて、図中左から顔画像を入力すると、画像上の狭い領域における単純な特徴から、段々と広い範囲の複雑な特徴が抽出されていきます。
これらのネットワークアーキテクチャには
Alexnet, VGGNet, GoogleNet, ResNet, SENet
など様々なものがあります。Face01 では ResNet を用いたデータを使用しています。
5.マッチング
特徴群から入力された顔が登録者であるか、または登録者の中に居ないかを識別します
この様にして合成された顔認証動画をご覧ください。
参照:よく分かる生体認証 一般社団法人日本自動認識システム協会編