
顔特徴量のエンコード時間について
こちらの記事は古くなっており非推奨となりました。
最新のドキュメントは以下から閲覧可能です。
・GitHub FACE01
・FACE01 document
今日は Face01 シリーズの内部についてほんの少しご紹介致します。
Face01 は登録された各顔画像ファイルに対して、特徴量をもとに 128 次元の特徴ベクトル化して数値データを作成する処理を行います。この処理を「エンコード」と呼びます。
エンコード時間の計測
今回エンコードにかかる時間を測定するため CUDA 環境下で 676 個の顔ファイルからエンコードにかかる時間を計測しました。
一枚のフレームから個人を特定するまでの認証速度は以下のように計測しました。
import time
time1 = time.time()
# 内部処理
time2 = time.time()
elapsed_time = time2 - time1検証環境
CUDA & AVX
Ubuntu 18.04.4
Python 3.6.9
Linux 4.15.0-66-generic
AMD Ryzen 5 1400
MemTotal 16GB
GeForce GT 710
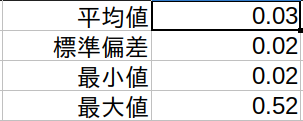
この時、平均時間は 0.03 秒でした。
CUDA 環境でない場合の計測結果は 0.3 秒でした。実質 10 倍の時間差があります。
もし可能であるならば、CUDA が使える環境のほうが 10 倍速いということになります。
それほど時間がかかるわけではありませんし、エンコードは起動時のみ時間がかかるのであまり問題はありませんが、何度も実験をしたりデモ動画をお見せしたりするときにはエンコード時間は短いに越したことはありません。
特徴量を外部ファイルとして保存、読み込み
特徴ベクトルの配列をテキストデータとして保存しておけば、エンコードにかかる時間はなくなります。
数値計算ライブラリ NumPy の savetxt と loadtxt を使うことにより、エンコードした顔画像データを csv 形式で保存することができます。
np.savetxt('example.txt', face_encodings, fmt='%s', delimiter=',')
np.loadtxt( 'example.txt', delimiter=',' )
これによりエンコードする時間を省けますので、初期ロード時間は体感では感じません。
上記の機能は Face01 シリーズ全てに搭載されておりますのでユーザ側で何かすることはありません。
顔画像が初期エンコードされると npKnown.txt ファイルが作成されます。この中に上記記事中の 128 次元データが格納されています。一度目の起動時には初期エンコードが行われこの npKnown.txt が作成されます。二度目からの起動には npKnown.txt が最初から読み込まれるため起動時間が劇的に早くなります。

ただし、顔画像格納フォルダである「pictures_of_people_i_know」の中を変更した場合には npKnown.txt を削除してから起動してください。「pictures_of_people_i_know」の中の顔画像ファイルと npKnown.txt の内容に違いが起こらないようにするためです。安全のため、違いが起こっている場合にはアプリケーションを停止させる仕様となっています。
以上です。
最後までお読み頂きありがとうございました。

