
【ドキュメント】オプション変数詳細 FACE01 GRAPHICS ver.1.2.5
こちらの記事は古くなっており非推奨となりました。
最新のドキュメントは以下から閲覧可能です。
・GitHub FACE01
・FACE01 document
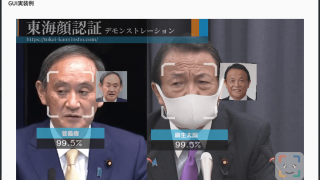
FACE01 GRAPHICSのオプション変数について解説します。ここではFACE01 GRAPHICSバージョン1.2.5を例に取ります。
メソッドなどを含めたオプション変数まわりの概略はこちらのページからご参照下さい。FACE01 GRAPHICS ver.1.2.5からオプション変数の一部が変更されています。ご注意下さい。
FACE01 GRAPHICSは外部ファイルをから呼び出す際にオプション変数を直接指定します。バージョン1.2.0よりGUIによる設定ウィンドウ(SETTING_MANAGER)からオプション変数の変更を行えます。(付属していない場合もあります)
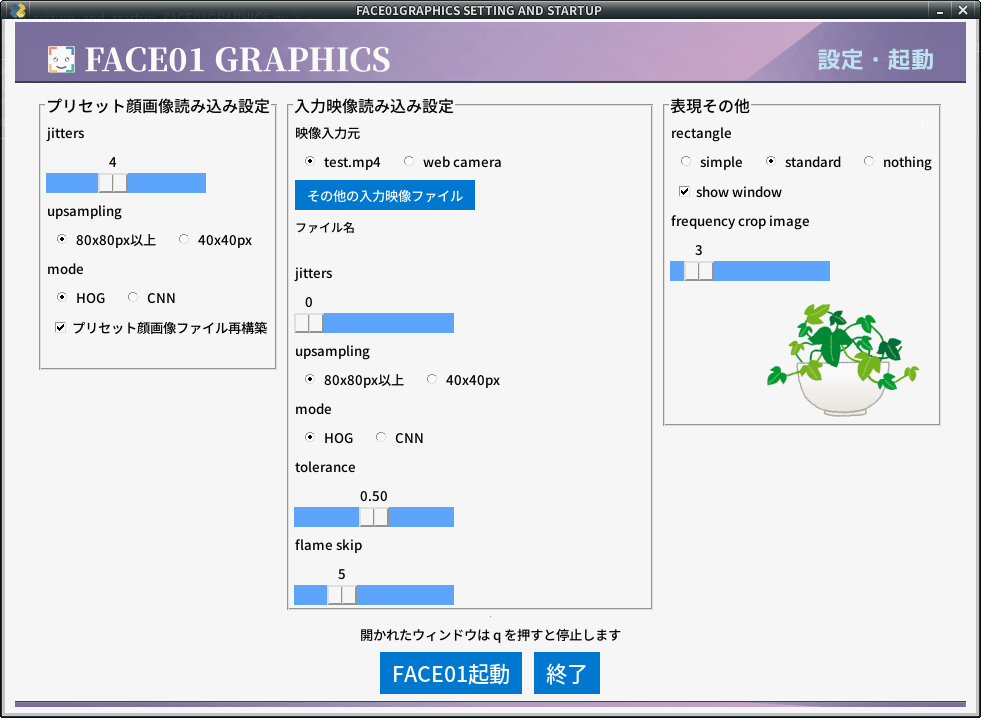
# 変数設定 ==========================
## 説明(default値)
## 閾値(0.5)
tolerance=0.45
## ゆらぎ値(0)
jitters=0
## 登録顔画像のゆらぎ値(10)
priset_face_images_jitters=10
## 最小顔検出範囲(0)
upsampling=0
## 顔検出方式(cnn)
mode='cnn'
## フレームドロップ率(-1)
frame_skip=-1
## 入力映像(test.mp4)
movie='some_people.mp4'
## 顔枠表示シンプル(False)
rectangle=False
## 顔枠表示標準(True)
target_rectangle=True
## 簡易ウィンドウ表示(False)
show_video=False
## 顔画像保存割合(10)
frequency_crop_image=10
## 表示エリア(NONE)
set_area='NONE'
## 収差学習<未実装>(False, 1)
face_learning_bool=False
how_many_face_learning_images=1
## 映像データ標準出力(False)
output_frame_data_bool=False
## 映像データプロパティ表示(False)
print_property=False
## 単一処理時間表示(False)
calculate_time=True
## 映像データ大きさ
SET_WIDTH=500
# ===================================オプション変数は呼び出す側に自由度を与えますが、反対に顔認証のアルゴリズムや各々のオプション変数の働きが分かっていないと期待しない動作になってしまいます。
内部があまりよく理解できていない最初は「オプション変数を変更しない」というのも一つの手です。オプション変数を変更しなくてもある程度よろしくやってくれるようになっています。(デフォルト値が適用される)
では一つづつオプション変数を確認していきましょう。
目次
- 1 各オプション変数の働き
- 1.1 tolerance
- 1.2 jitters
- 1.3 priset_face_images_jitters
- 1.4 upsampling
- 1.5 mode
- 1.6 model
- 1.7 frame_skip
- 1.8 movie
- 1.9 rectangle, target_rectangle
- 1.10 show video
- 1.11 frequency_crop_image
- 1.12 set_area
- 1.13 face_learning_bool, how_many_face_learning_images
- 1.14 output_frame_data_bool
- 1.15 print_property
- 1.16 calculate_time
- 1.17 SET_WIDTH
- 2 戻り値
- 3 まとめ
各オプション変数の働き
tolerance
閾値。デフォルト値0.5
0.6を基準としてトレーニングしてあり、これより大きければ他人と判断されます。
閾値以上の distance ( 顔データ間の距離 ) は足切りされます。
jitters
ゆらぎ値。デフォルト値0
入力画像を受け取り、色を乱し、ランダムな移動、回転、スケーリングを適用します。
jitters の値を大きくするほどランダムな変換の平均値をとるようになります。
しかしながら大きな値をとることによって入力画像が不確かなものになっていくこと、処理時間が長くなることが懸念されます。
(参照箇所:…/dlib/python_examples/face_jitter.py)
priset_face_images_jitters
登録顔画像のゆらぎ値。デフォルト値10
登録顔画像の計算は最初の1回しか行われないためデフォルト値を10としています。
upsampling
最小顔検出範囲。デフォルト値0
1フレームの画像のうち、顔探索するピクセル範囲を決定する変数。
80×80では80X80ピクセル位上の範囲を、40×40 ピクセルでは40X40ピクセル以上の範囲を顔探索します。
1フレームごとにより細かく顔探索するように指示するため、処理時間とトレードオフになります。
下の例ではそれぞれの顔は80X80ピクセルの面積以上になっています。この場合は80×80を選択する(upsampling=0)ことで良好な結果を出します。

mode
顔検出方式。デフォルト値cnn
顔検出にCNN方式または HOG方式のどちらを用いるかを選びます。
CNN: Convolutional Neural Network
HOG: Histogram of Oriented Gradients
CPUのみの場合HOG方式の方が処理速度は高くなります。反対にNvideaのGPUが使える場合、CNN方式の処理速度が高くなります。
( …/dlib/python_examples/dnn_mmod_face_detection_ex.cpp 参照 )
HOG方式はマスクをした顔の検出を苦手とします。
マスクをした顔を顔検出する場合はCNN方式を選択すると良い結果を出します。CNNまたはHOGを指定する際は小文字にして下さい。
model
顔検出には2つの方式があります
small: 5-point landmark model
large: 68-point landmark model
ライセンスの問題からsmall のみの選択になっています。FACE01 GRAPHICS ver.1.2.5よりこのオプション変数は変更不可となっています。
frame_skip
フレームドロップの割合。デフォルト値-1
-1を指定すると自動的にframe_skip値を内部で変更します。
入力が 30fps の場合 frame_skip=2 では 15fps となります。処理するコンピュータの性能によってさばけるフレーム数は異なります。CPUしか使えない状況でmodeにCNN方式を選んだ時などに負荷がかかって処理速度が落ちる場合、このオプション変数によりフレームを適切にドロップします。
処理速度を十分に満たさないマシンをご使用になる場合は-1以外を指定する必要があります。
movie
入力映像を指定します。デフォルト値test.mp4
動画ファイル(mp4, aviなど)、Webカメラ、httpプロトコルを使ったストリームのうちから指定します。
入力映像元をhogefuga.mp4ファイルにする場合、hogefuga.mp4を指定します。Webカメラを用いる時は0(int)を指定します。まれに0を指定した場合でもWebカメラが繋がらないバグが報告されております。このバグについてはFACE01 GRAPHICS ver.1.2.6以降にフィックスされる予定です。
rectangle, target_rectangle
顔枠表示指定。顔周囲に枠を描画するかどうか・どの様な枠にするかを指定します。
- rectangle=True; target_rectangle=False
四角形を描画する - rectangle=False; target_rectangle=True
通常枠を描画する - rectangle=False; target_rectangle=False
枠を表示しない

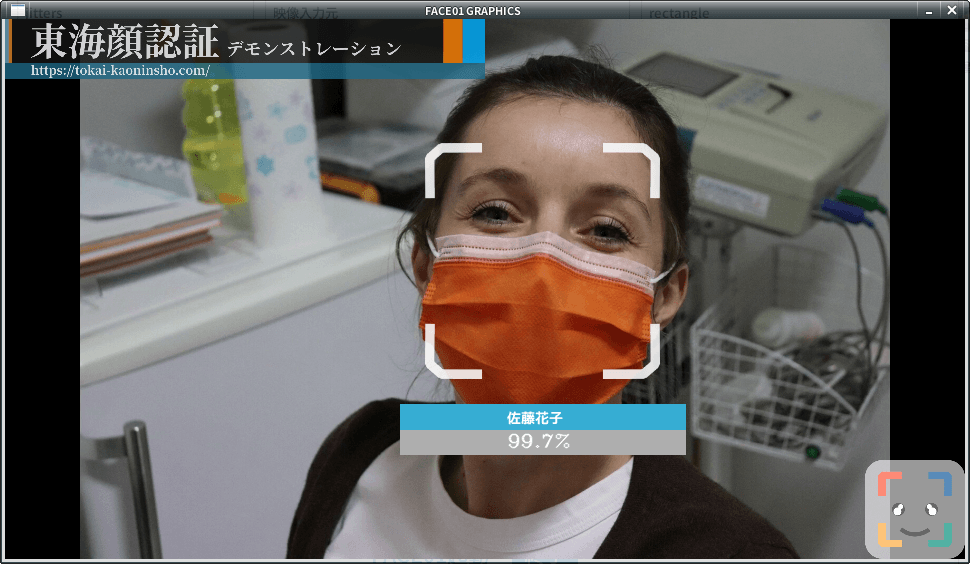
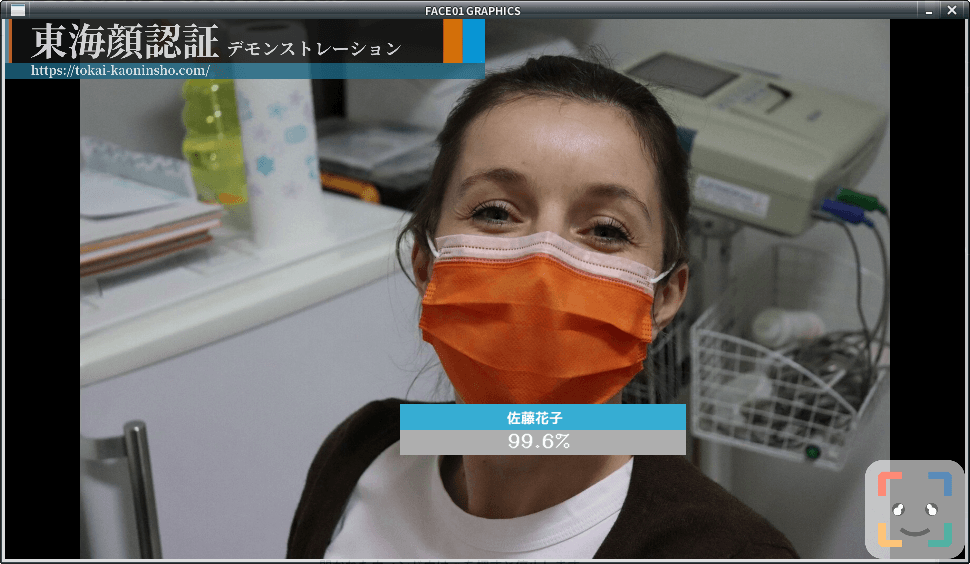
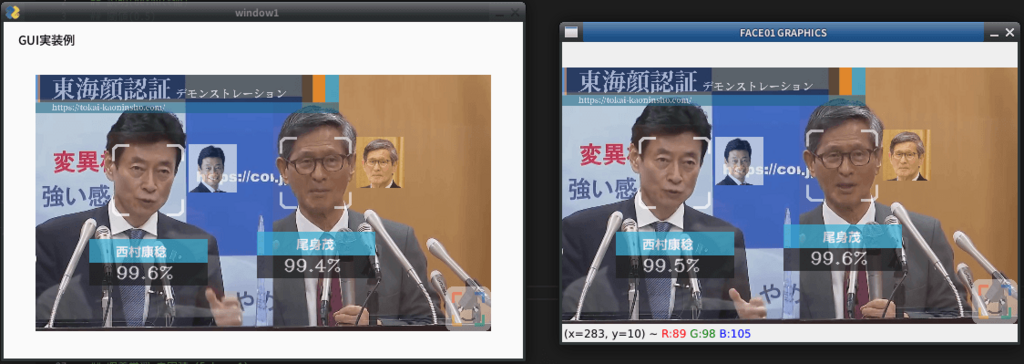
show video
openCV 由来のウィンドウ表示をするかしないかを選べます。デフォルト値False
frequency_crop_image
n 枚のフレームごとに 1 つの顔画像ファイルを出力することを指定。デフォルト値10
これまで(バージョン 1.1.3 )は 1 フレームごとに output として顔をクロップした顔画像ファイルを出力していましたが、これだと I/O 速度が律速ポイントとなってしまいます。frequency_crop_imageを指定することで運用するマシンのi/o速度がFACE01 GRAPHICSの処理速度に影響を与えることを抑える効果があると同時にoutputフォルダが顔画像ファイルであふれることを予防します。
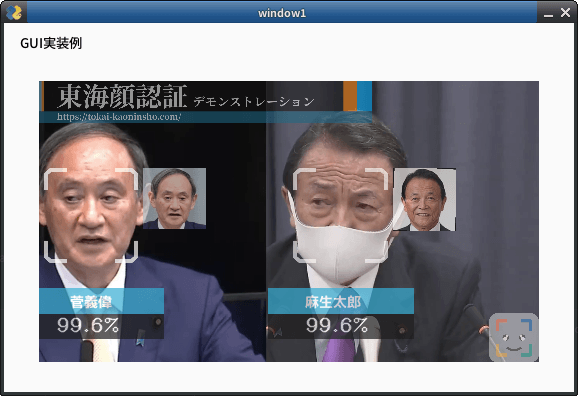
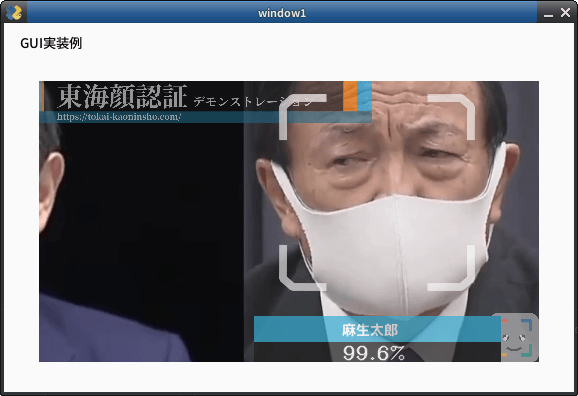
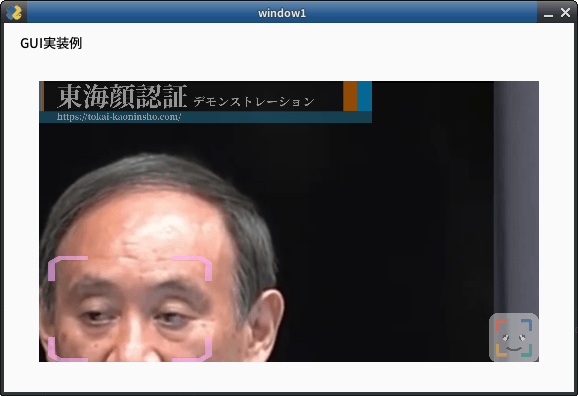
set_area
入力された映像のうち処理する範囲を限定します。入力映像のうち一部分しか使いたくない場合に使用します。デフォルト値NONE
NONE, TOP_LEFT, TOP_RIGHT, CENTER, BOTTOM_LEFT, BOTTOM_RIGHTから指定します。下図のようになります。
face_learning_bool, how_many_face_learning_images
FACE01 GRAPHICS ver.1.2.5では実験的位置づけです。レンズ歪曲収差の補正に使われます。デフォルト値のままにして下さい。
デフォルト値
face_learning_bool=False
how_many_face_learning_images=1
output_frame_data_bool
標準出力に処理済み映像データを出力します。デフォルト値False
print_property
入力映像のプロパティを表示して終了します。デフォルト値False
calculate_time
シングルコア処理下での1フレームにかかる処理時間を計測します。デフォルト値False
通常はマルチコアを使用(並行処理)したりマルチスレッドを使用(並列処理)前提で設定ファイルを書きますのでここで出る値がそのまま使えるわけではありません。目安としてお使い下さい。
SET_WIDTH
入力映像をリサイズします。デフォルト値800
マシンの処理性能や作成するアプリケーションにあわせて設定して下さい。
戻り値
FACE01 GRAPHICS ver.1.2.5のface_attestation()メソッドから得られる戻り値はジェネレーターオブジェクトであり反復処理によって辞書の集合を得られます。
辞書のキーは以下のとおりです。
name, pict, date, img, location, percentage_and_symbol, stream
以下のコードによりそれぞれの値が得られます。
# 抜粋
for x in xs:
print(f"name: {x['name']}")
print(f"pict: {x['pict']}")
print(f"date: {x['date']}")
print(f"location: {x['location']}")
print(f"percentage: {x['percentage_and_symbol']}")
print(f"img: {x['img']}")
break
# 出力結果
name: 安倍晋三
pict: output/安倍晋三_99.6%_2021,08,13,13,34,52,183913_0.24.png
date: 2021,08,13,13,34,52,183913
location: (92, 283, 171, 204)
percentage: 99.6%
img: [[[108 94 62]
[108 94 62]
[ 82 94 93]
...- name
顔認証処理の結果返される名前。未登録の顔の場合は「Unknown」 - pict
出力される顔画像ファイル名 - date
顔認証処理された日付時刻 - img
numpy形式の処理済みフレーム画像データ - location
顔が存在する座標。(top,right,bottom,left)のタプル - percentage
顔認証処理により何%の確率でその人物か数値で返す - stream
output_frame_data_bool=Trueと指定した時のみ出力されるnumpy形式の処理済みフレーム画像データ
まとめ
こちらのページもご参照下さい。もし疑問点・不明な点があればお問い合わせからご連絡いただけると幸いです。
最後までお読み頂きありがとうございました。

