
顔認証を使った「顔が似てる芸能人ランキング」
約650人の芸能人の顔データを使って、芸能人(と著名人)の似ている組み合わせ(なんと20万組以上!)を顔認証エンジンを使用したプログラムを書いて検証してみました。最初に結論を載せて、後半にソースコードとその説明、最後に目的を解説します。
追記: FACE01 1.4.14 に合わせてコードを訂正しました。
この記事では、汎用顔学習モデル(dlib_face_recognition_resnet_model_v1.dat)を用いて、似ている日本人の類似度を算出しています。
汎用顔学習モデルは、日本人、特に若年女性の判別において「偽陽性」を出す傾向にあります。この問題に対処するため、東海顔認証は日本人専用のAI顔学習モデル「JAPANESE FACE」を開発しました。
「JAPANESE FACE」を用いた再実験の結果を日本人顔認識のための新たな学習モデルを作成 ~ EfficientNetV2ファインチューニング ~ にて掲載しております。こちらのAI顔学習モデルでは、記事中で取り上げた組み合わせ全てにおいて「明確に別人」という判定結果が出ております。こちらの記事と併せて、どうぞご参照下さい。
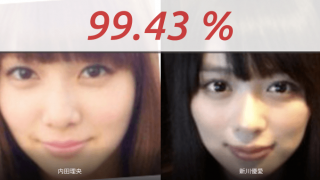
検証結果
同一人物の違う写真がある場合、当たり前ですが本人同士がマッチしてしまいます。ここでは強制的に「他人どうし」になるように調整してあります。
1 位 大森南朋_default.png 新井浩文_default.png 99.44 %
2 位 新川優愛_default.png 内田理央_default.png 99.43 %
3 位 金正恩_10.png 馬場園梓_default.png 99.38 %
4 位 西村康稔_5.png 池田清彦_default.png 99.37 %
5 位 金正恩_10.png 畑岡奈紗_default.png 99.37 %
6 位 椎名林檎_3.png 有働由美子_default.png 99.37 %
7 位 波瑠_default.png 入山杏奈_default.png 99.36 %
8 位 浅田舞_default.png 浅田真央_default.png 99.36 %
9 位 麻木久仁子_default.png 有働由美子_default.png 99.35 %
10 位 加藤勝信_001.png 萩生田光一_001.png 99.31 %「実はこのふたり、いとこなんです」って言われたら納得してしまうかもしれません。(実際は違いますが…)
1 位 大森南朋 新井浩文 99.44 %


2 位 新川優愛 内田理央 99.43 %


3 位 金正恩 馬場園梓 99.38 %
すごく綺麗にお化粧して変装したら似ているかもしれません。


4 位 西村康稔 池田清彦 99.37 %
30年後はそっくりかもしれません。顔のパーツはそっくりですのでありえるかも。


5 位 金正恩 畑岡奈紗 99.37 %
目鼻立ちのパーツはイケメンなのかもしれません。中性的なのでしょうか。

6 位 椎名林檎 有働由美子 99.37 %


7 位 波瑠 入山杏奈 99.36 %


8 位 浅田舞 浅田真央 99.36 %
姉妹であられるとのことです。


追検証
後日画像数を増やして追検証してみました。

この記事では、汎用顔学習モデル(dlib_face_recognition_resnet_model_v1.dat)を用いて、似ている日本人の類似度を算出しています。
汎用顔学習モデルは、日本人、特に若年女性の判別において「偽陽性」を出す傾向にあります。この問題に対処するため、東海顔認証は日本人専用のAI顔学習モデル「JAPANESE FACE」を開発しました。
「JAPANESE FACE」を用いた再実験の結果を日本人顔認識のための新たな学習モデルを作成 ~ EfficientNetV2ファインチューニング ~ にて掲載しております。こちらのAI顔学習モデルでは、記事中で取り上げた組み合わせ全てにおいて「明確に別人」という判定結果が出ております。こちらの記事と併せて、どうぞご参照下さい。
本人同士ではどうなるか
他人の空似より本人同士の類似度は当然高くなります。本人の写真が2枚以上存在する人は14人です。検証してみましょう。
1 位 小泉進次郎_4.png 小泉進次郎_6.png 99.71 %
2 位 金正恩_3.png 金正恩_2.png 99.67 %
3 位 金正恩_4.png 金正恩_default.png 99.66 %
4 位 金正恩_1.png 金正恩_4.png 99.57 %
5 位 神木隆之介_2.png 神木隆之介_1.png 99.52 %
6 位 金正恩_4.png 金正恩_6.png 99.5 %
7 位 西村康稔_5.png 西村康稔_3.png 99.5 %
8 位 尾身茂_default.png 尾身茂_1.png 99.47 %
9 位 安倍晋三_face_learning_1.png 安倍晋三_default.png 99.47 %
10 位 神木隆之介_default.png 神木隆之介_1.png 99.46 %他人の空似の場合より、パーセントの数値が高くなっていることに注目してください。
1 位 小泉進次郎 小泉進次郎 99.71 %


2 位 金正恩 金正恩 99.67 %


3 位 金正恩 金正恩 99.66 %


4 位 金正恩 金正恩 99.57 %

5 位 神木隆之介 神木隆之介 99.52 %


6 位 金正恩 金正恩 99.50 %

7 位 西村康稔 西村康稔 99.50 %


8 位 尾身茂 尾身茂 99.47 %


9 位 安倍晋三 安倍晋三 99.47 %


10 位 神木隆之介 神木隆之介 99.46 %

ソースコードと解説
ここからは技術的なお話です。
ソースコード
import itertools
import sys
import numpy as np
# FACE01ライブラリのインポート
sys.path.insert(1, 'PATH TO FACE01 DIRECTORY')
from face01lib import Calc # type: ignore
from face01lib import load_preset_image # type: ignore
Cal_obj = Calc.Cal()
def make_dict(dir_path):
known_face_encodings_list, known_face_names_list = \
load_preset_image.load_preset_image(
dir_path,
preset_face_imagesDir=dir_path,
upsampling=0,
jitters=0,
mode='cnn',
model='small'
)
# 辞書へ要素を追加
name_encoding_dict = {}
for counter in range(0, len(known_face_names_list), 1):
name_encoding_dict[known_face_names_list[counter]] = known_face_encodings_list[counter]
return name_encoding_dict
def distances_per_pair(name_encoding_dict):
pair_distance_dict = {} # 'pair_distance_dict' is 'pair: distance'
distance_list = []
print(
f'Search for combinations of {len(list(itertools.combinations(name_encoding_dict.keys(), 2)))} pairs.'
)
for pair in list(itertools.combinations(name_encoding_dict.keys(), 2)):
distance = np.linalg.norm(name_encoding_dict[pair[0]] - name_encoding_dict[pair[1]], ord=2, axis=None)
pair_distance_dict[pair] = distance
distance_list.append(distance)
distance_list.sort(reverse=False)
cnt = 0
for distance_item in distance_list:
for key, value in pair_distance_dict.items():
if value==distance_item:
first, second = key[0], key[1]
first, _first = first.split('_', 1)
second, _second = second.split('_', 1)
if first==second:
first = first + '_' + _first
second = second + '_' + _second
print(
cnt + 1, '位',
first,
second,
round(Cal_obj.to_percentage(value), 2),'%'
)
cnt+=1
if cnt==10:
exit()
if __name__ == '__main__':
dir_path='PATH TO DIRECTORY'
name_encoding_dict = make_dict(dir_path)
distances_per_pair(name_encoding_dict)ソースコード解説
import itertools
import sys
import numpy as np
# FACE01ライブラリのインポート
sys.path.insert(1, 'PATH TO FACE01 DIRECTORY')
from face01lib import Calc # type: ignore
from face01lib import load_preset_image # type: ignore
from face01lib.api import Dlib_api # type: ignore
Dlib_api_obj = Dlib_api()
Cal_obj = Calc.Cal()
組み合わせ問題にitertoolsライブラリを使います。load_preset_imageメソッドとto_percentageメソッドはFACE01のライブラリから使用しています。
def make_dict(dir_path):
known_face_encodings_list, known_face_names_list = \
load_preset_image.load_preset_image(
dir_path,
preset_face_imagesDir=dir_path,
upsampling=0,
jitters=0,
mode='cnn',
model='small'
)make_dict()ではFACE01のライブラリであるload_preset_imageメソッドを呼び出しています。引数はiniファイルに設定として記述しますが、ここではコードが長くなるので固定値を代入しています。
# 辞書へ要素を追加
name_encoding_dict = {}
for counter in range(0, len(known_face_names_list), 1):
name_encoding_dict[known_face_names_list[counter]] = known_face_encodings_list[counter]
return name_encoding_dict
辞書name_encoding_dictを作成して名前のリストとエンコーディングされた顔データを辞書の要素として追加していきます。len(known_face_names_list)分、つまり約650人全てを辞書データとして登録します。
def distances_per_pair(name_encoding_dict):
pair_distance_dict = {} # 'pair_distance_dict' is 'pair: distance'
distance_list = []distances_per_pair()では先のmake_dict()の返り値、即ち辞書オブジェクトを引数にとります。
print(
f'Search for combinations of {len(list(itertools.combinations(name_encoding_dict.keys(), 2)))} pairs.'
)
for pair in list(itertools.combinations(name_encoding_dict.keys(), 2)):
distance = np.linalg.norm(name_encoding_dict[pair[0]] - name_encoding_dict[pair[1]], ord=2, axis=None)
itertools.combinations()で順番関係なしの組み合わせを作成しています。続くnp.linalg.norm()ではエンコードされた顔データ同士のユークリッド距離を計算しています。L2ノルムなのでord=2、それぞれひとつづつの比較なのでaxis=Noneです。これらの構文は機械学習で度々用いられます。
pair_distance_dict[pair] = distance
distance_list.append(distance)
distance_list.sort(reverse=False)
cnt = 0
for distance_item in distance_list:
for key, value in pair_distance_dict.items():
if value==distance_item:
first, second = key[0], key[1]
first, _first = first.split('_', 1)
second, _second = second.split('_', 1)
if first==second:
first = first + '_' + _first
second = second + '_' + _second
print(
cnt + 1, '位',
first,
second,
round(Cal_obj.to_percentage(value), 2),'%'
)
cnt+=1
if cnt==10:
exit()書捨てのようになっておりますが。顔距離のリストを短い順からソートして、顔距離を値として辞書のkeyを検索し、10位までを標準出力しています。見やすいようにパーセント表示は四捨五入しています。
最後に
いかがだったでしょうか。
今回の検証実験は一見興味本位の様に見えますが目的がしっかりとあります。顔サンプル中に顔距離の小さい顔どうしがあった場合、映像データのクオリティや表情によっては誤検出が発生します。似た顔を予め把握して対策をとることは顔認証に於いて非常に重要な前処理です。あまりにも顔距離が近い場合、サンプルとなる顔データをとりなおしたり、機械学習にかけて分類する必要があるかもしれません。
以上です。最後までお読み頂きありがとうございました。

