
Dlib顔学習モデルの、若年日本人女性データセットにおける性能評価

目次
はじめに
Dlibの顔学習モデルであるdlib_face_recognition_resnet_model_v1.datと、日本人専用のAI顔学習モデルJAPANESE FACEの、若年日本人女性データセットにおける性能評価を行います。
Dlibの歴史と特徴
Dlibは、元々はC++で書かれた機械学習とデータ解析のためのオープンソースライブラリです。2002年にDavis Kingによって開発が始まりました。Dlibは、顔認証の分野でよく知られていますが、その機能はそれだけにとどまりません。このライブラリは、画像処理、機械学習、自然言語処理、数値最適化といった多様なタスクに対応しています。C++で開発された本ライブラリはPythonバインディングも提供しています。dlib(GitHub)で、現在も開発が続けられています。
dlib_face_recognition_resnet_model_v1.dat
このモデルは、ResNetベースの深層学習モデルで、非常に高い精度で顔認証が可能です。2017年に提供が開始されました。
Labeled Faces in the Wild (LFW) データセットでの精度は99.38%と報告されています。このような高い精度が、Dlibとその顔認証モデルが広く採用される一因です。
face_recognitionライブラリ
face_recognitionは、Pythonで書かれた顔認証のためのライブラリで、Dlibの「dlib_face_recognition_resnet_model_v1.dat」を内部で使用しています。このライブラリは、Adam Geitgeyによって開発され、簡単なAPIで高度な顔認証が行えることから、多くのプロジェクトで使用されています。
dlib_face_recognition_resnet_model_v1.datの性能評価
この様にさまざまな顔認証プロジェクトで活用されているDlibの顔学習モデルですが、若年日本人女性の顔画像に対しては、どの程度の精度が出るのでしょうか。このモデルの性能を評価するために、若年日本人女性の顔画像を用意し、ROC-AUCを計算しました。
一般日本人に対しての性能評価
著名日本人の顔画像データベースから、ランダムに300枚の画像を選択し、一般日本人の顔画像データセットを作成しました。このデータセットに対して、dlib_face_recognition_resnet_model_v1.datを用いて顔認証を行い、ROC-AUCを計算しました。その結果が以下になります。
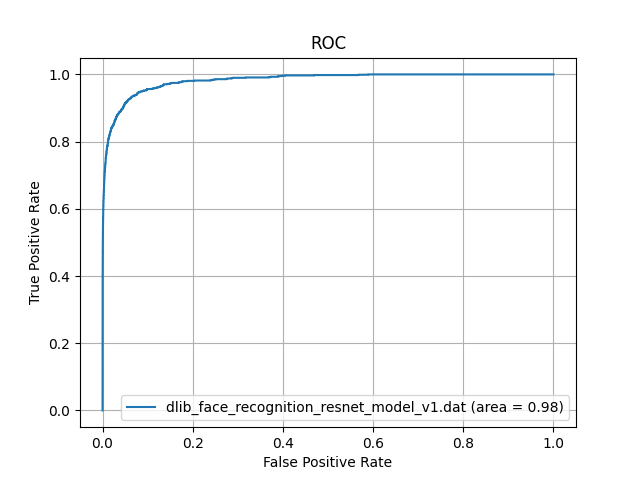
一般日本人に対して、dlib_face_recognition_resnet_model_v1.datのAUCは0.98であり、非常に高い精度を示しています。
若年日本人女性に対しての性能評価
著名日本人の顔画像データベースから、とくに若年女性の顔画像をランダムに300枚選択し、若年日本人女性の顔画像データセットを作成しました。このデータセットに対して、dlib_face_recognition_resnet_model_v1.datを用いて顔認証を行い、ROC-AUCを計算しました。その結果が以下になります。
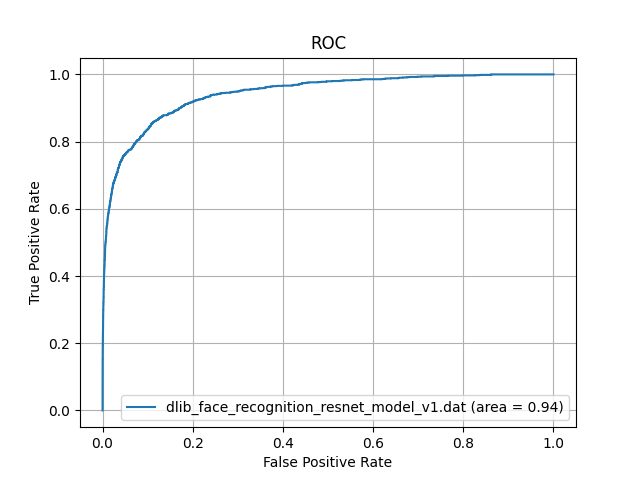
一般日本人に対して、若年日本人女性の顔画像を用いて性能評価をしたところ、AUCが0.98から0.94に低下しました。
これはDlibの顔学習モデルが、face scrub datasetやVGGデータセットを主に使用しているところが原因と考えられます。これらのデータセットには、若年日本人女性の顔画像がほとんど含まれていないため、若年日本人女性の顔画像に対しては、性能が低下すると考えられます。(High Quality Face Recognition with Deep Metric Learningを参照)
JAPANESE FACEについて
この問題を解決するため、独自の日本人顔データセットを用いて学習したモデルがJAPANESE FACEです。このモデルはEfficientNetV2にArcFaceLossを適用して作成されました。作成の詳細は、日本人顔認識のための新たな学習モデルを作成 ~ EfficientNetV2ファインチューニング ~という記事で詳しく解説しています。
このモデルを使って、Dlibの学習モデルと比較した結果を以下に示します。
一般日本人に対しての性能評価
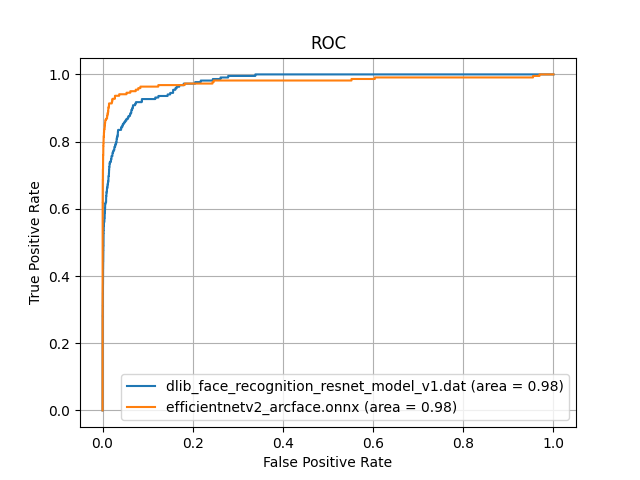
Dlibの学習モデルと比較して、AUCが0.98であり、同等の性能を示しています。
若年日本人女性に対しての性能評価
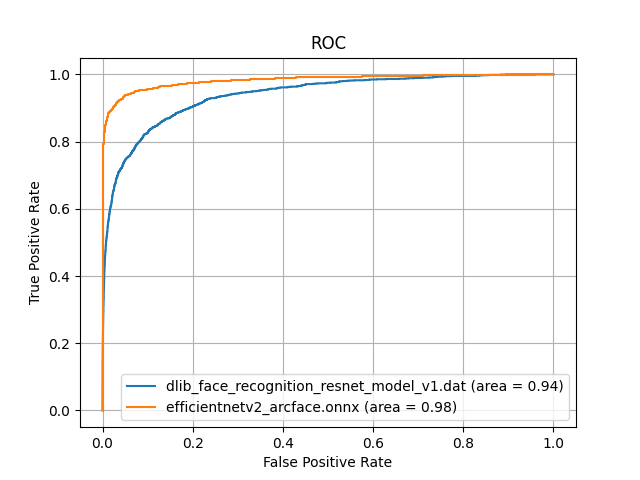
逆に、若年日本人女性の顔画像に対しては、DlibのAUCが0.94に対し、JAPANESE FACEは0.98を維持しています。
ROC-AUCグラフ作成コード
それでは、ROC-AUCグラフを作成するコードを紹介します。
Dlibは、類似度をユークリッド距離を使って計算します。対してJAPANESE FACEは、類似度をコサイン類似度を使って計算します。そのため、類似度計算は別関数として定義します。
また、ROC曲線の計算と描画において、Dlibの類似度を負にする必要があります。Dlibの場合、ROC曲線の計算において、スコアが大きいほど、真陽性率が大きくなります。
ROC曲線(Receiver Operating Characteristic curve)を描画する際には、通常、スコアが高いほど真陽性率(True Positive Rate, TPR)が高くなるように設計されています。しかし、ユークリッド距離の場合、距離が短い(すなわち、スコアが低い)ほど2つの顔が同一人物である可能性が高くなります。
このような場合、スコアが低いほど真陽性率が高くなるようにROC曲線を描画する必要があります。そのため、スコアを負にして、低いスコアが高いスコアとして扱われるようにしています。
具体的には、roc_curve関数はスコアが高いほどより良い(真陽性率が高くなる)と解釈します。ユークリッド距離の場合、距離が短い(スコアが低い)ほどより良いと解釈したいので、スコアを負に変換しています。これにより、roc_curve関数が低いユークリッド距離を高いスコアとして正しく解釈できるようになります。
import os
from itertools import combinations
import cupy as cp
import dlib
import matplotlib.pyplot as plt
import numpy as np
import onnx
import onnxruntime as ort
import torchvision.transforms as transforms
from PIL import Image
from sklearn.metrics import auc, roc_curve
from tqdm import tqdm
# 顔検出器、顔特徴抽出器、顔ランドマーク検出器のロード
face_detector = dlib.get_frontal_face_detector()
face_recognition_model = dlib.face_recognition_model_v1("dlib_face_recognition_resnet_model_v1.dat")
shape_predictor = dlib.shape_predictor("shape_predictor_5_face_landmarks.dat") # 5点のランドマーク検出器
# 画像のディレクトリ
image_dir = "/home/terms/bin/pytorch-metric-learning/ROC用"
image_files = [os.path.join(image_dir, f) for f in os.listdir(image_dir) if f.endswith('.png')]
# Dlibの類似度判断の関数
def is_same_person_dlib(embedding1, embedding2):
# ユークリッド距離の計算
euclidean_distance = np.linalg.norm(np.array(embedding1) - np.array(embedding2))
return euclidean_distance
embeddings_dict_dlib = []
for image_file in tqdm(image_files):
name = os.path.splitext(os.path.basename(image_file))[0]
name = name.split('_')[0]
image = dlib.load_rgb_image(image_file)
detected_faces = face_detector(image, 1)
if detected_faces:
# 顔ランドマークの検出
shape = shape_predictor(image, detected_faces[0])
# 顔特徴の抽出
face_descriptor = face_recognition_model.compute_face_descriptor(image, shape)
embeddings_dict_dlib.append({name: face_descriptor})
# JAPANESE FACEの類似度判断の関数
def is_same_person_onnx(embedding1, embedding2):
embedding1 = cp.asarray(embedding1).flatten()
embedding2 = cp.asarray(embedding2).flatten()
cos_sim = cp.dot(embedding1, embedding2) / (cp.linalg.norm(embedding1) * cp.linalg.norm(embedding2))
return cos_sim.get()
# 画像の前処理を定義
mean_value = [0.485, 0.456, 0.406]
std_value = [0.229, 0.224, 0.225]
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(
mean=mean_value,
std=std_value
)
])
# JAPANESE FACEモデルをロード
model_name = 'efficientnetv2_arcface.onnx'
onnx_model = onnx.load(model_name)
ort_session = ort.InferenceSession(model_name)
# 入力名を取得
input_name = onnx_model.graph.input[0].name
# 画像を読み込み、前処理を行い、モデルで推論を行う
embeddings_dict_onnx = []
for image_file in tqdm(image_files):
name = os.path.splitext(os.path.basename(image_file))[0]
name = name.split('_')[0]
image = Image.open(image_file).convert('RGB')
image = transform(image)
image = image.unsqueeze(0) # バッチ次元を追加
image = image.numpy()
embedding = ort_session.run(None, {input_name: image})[0]
embeddings_dict_onnx.append({name: embedding})
# embeddings_dictの各要素のペアを作成 (Dlibの場合)
pair_dlib = list(combinations(embeddings_dict_dlib, 2))
labels_dlib = [1 if list(pair_dlib[i][0].keys())[0] == list(pair_dlib[i][1].keys())[0] else 0 for i in range(len(pair_dlib))]
scores_dlib = [is_same_person_dlib(pair_dlib[i][0][list(pair_dlib[i][0].keys())[0]], pair_dlib[i][1][list(pair_dlib[i][1].keys())[0]]) for i in range(len(pair_dlib))]
# embeddings_dictの各要素のペアを作成 (JAPANESE FACEの場合)
pair_onnx = list(combinations(embeddings_dict_onnx, 2))
labels_onnx = [1 if list(pair_onnx[i][0].keys())[0] == list(pair_onnx[i][1].keys())[0] else 0 for i in range(len(pair_onnx))]
scores_onnx = [is_same_person_onnx(pair_onnx[i][0][list(pair_onnx[i][0].keys())[0]], pair_onnx[i][1][list(pair_onnx[i][1].keys())[0]]) for i in range(len(pair_onnx))]
# ROC曲線の計算と描画 (Dlibの場合)
fpr_dlib, tpr_dlib, _ = roc_curve(labels_dlib, [-x for x in scores_dlib]) # スコアを負にする
roc_auc_dlib = auc(fpr_dlib, tpr_dlib)
plt.plot(fpr_dlib, tpr_dlib, label=f'dlib_face_recognition_resnet_model_v1.dat (area = {roc_auc_dlib:.2f})')
# ROC曲線の計算と描画 (JAPANESE FACEの場合)
fpr_onnx, tpr_onnx, _ = roc_curve(labels_onnx, scores_onnx)
roc_auc_onnx = auc(fpr_onnx, tpr_onnx)
plt.plot(fpr_onnx, tpr_onnx, label=f'efficientnetv2_arcface.onnx (area = {roc_auc_onnx:.2f})')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC')
plt.grid(True)
plt.legend(loc="lower right")
plt.show()F1-score
続いてF1-scoreを比較します。こちらは若年日本人女性のデータセットのみを比較します。
Dlib
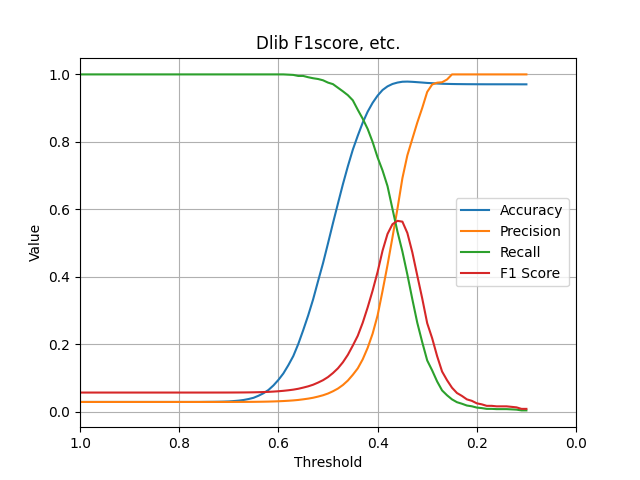
Dlibのブログでは「The network training started with randomly initialized weights and used a structured metric loss that tries to project all the identities into non-overlapping balls of radius 0.6.」と書いてあるとおり、閾値を0.6としています。しかし、若年日本人女性のデータセットを対象とした場合、0.35が最適な閾値ということが、グラフから分かります。
この場合でも、F1-scoreは0.55程度の、あまり高い値とは言えない結果となりました。
F1-scoreグラフ作成コード
import os
from itertools import combinations
import dlib
import matplotlib.pyplot as plt
import numpy as np
from sklearn.metrics import (accuracy_score, f1_score, precision_score,
recall_score)
from tqdm import tqdm
# 顔検出器、顔特徴抽出器、顔ランドマーク検出器のロード
face_detector = dlib.get_frontal_face_detector()
face_recognition_model = dlib.face_recognition_model_v1("dlib_face_recognition_resnet_model_v1.dat")
shape_predictor = dlib.shape_predictor("shape_predictor_5_face_landmarks.dat") # 5点のランドマーク検出器
# 画像のディレクトリ
image_dir = "/home/terms/bin/pytorch-metric-learning/ROC用"
image_files = [os.path.join(image_dir, f) for f in os.listdir(image_dir) if f.endswith('.png')]
# 類似度判断の関数(ユークリッド距離を返す)
def is_same_person(embedding1, embedding2):
# ユークリッド距離の計算
euclidean_distance = np.linalg.norm(np.array(embedding1) - np.array(embedding2))
return euclidean_distance
embeddings_dict = []
for image_file in image_files:
name = os.path.splitext(os.path.basename(image_file))[0]
name = name.split('_')[0]
image = dlib.load_rgb_image(image_file)
detected_faces = face_detector(image, 1)
if detected_faces:
# 顔ランドマークの検出
shape = shape_predictor(image, detected_faces[0])
# 顔特徴の抽出
face_descriptor = face_recognition_model.compute_face_descriptor(image, shape)
embeddings_dict.append({name: face_descriptor})
# embeddings_dictの各要素のペアを作成
pair = list(combinations(embeddings_dict, 2))
labels = [1 if list(pair[i][0].keys())[0] == list(pair[i][1].keys())[0] else 0 for i in range(len(pair))]
scores = [is_same_person(pair[i][0][list(pair[i][0].keys())[0]], pair[i][1][list(pair[i][1].keys())[0]]) for i in range(len(pair))]
labels_scores = list(zip(labels, scores))
# 閾値ごとの結果を格納するリスト
accuracies = []
precisions = []
recalls = []
f1_scores = []
thresholds = np.arange(0.1, 1.1, 0.01)
true_labels = [label for label, _ in labels_scores]
for threshold in tqdm(thresholds):
predicted_labels = [1 if score <= threshold else 0 for _, score in labels_scores]
accuracy = accuracy_score(true_labels, predicted_labels)
accuracies.append(accuracy)
precision = precision_score(true_labels, predicted_labels)
precisions.append(precision)
recall = recall_score(true_labels, predicted_labels)
recalls.append(recall)
f1 = f1_score(true_labels, predicted_labels)
f1_scores.append(f1)
# 結果をグラフ化
plt.plot(thresholds, accuracies, label='Accuracy')
plt.plot(thresholds, precisions, label='Precision')
plt.plot(thresholds, recalls, label='Recall')
plt.plot(thresholds, f1_scores, label='F1 Score')
# x軸の範囲を反転
plt.xlim(1.0, 0)
plt.xlabel('Threshold')
plt.ylabel('Value')
plt.title('Dlib F1score, etc.')
plt.legend()
plt.grid(True)
plt.show()JAPANESE FACE
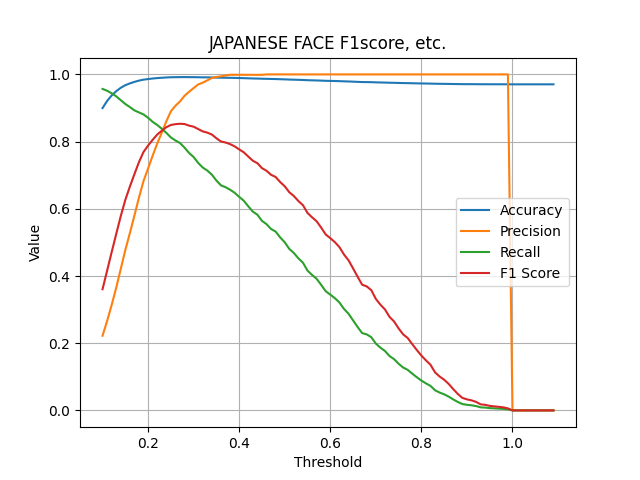
こちらのモデルでは、F1-scoreが0.8を超えています。これは、JAPANESE FACEが若年日本人女性のデータセットを用いて学習されているため、高い精度が出ていると考えられます。
F1-scoreグラフ作成コード
import os
import sys
from itertools import combinations
import cupy as cp
import matplotlib.pyplot as plt
import numpy as np
import onnx
import onnxruntime as ort
import torchvision.transforms as transforms
from PIL import Image
from sklearn.metrics import (accuracy_score, confusion_matrix, f1_score,
precision_score, recall_score)
from tqdm import tqdm
sys.path.append('/home/terms/bin/FACE01_IOT_dev')
from face01lib.utils import Utils # type: ignore
Utils_obj = Utils()
model_name = 'efficientnetv2_arcface.onnx'
# 画像の前処理を定義
mean_value = [0.485, 0.456, 0.406]
std_value = [0.229, 0.224, 0.225]
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(
mean=mean_value,
std=std_value
)
])
# ONNXモデルをロード
onnx_model = onnx.load(model_name)
ort_session = ort.InferenceSession(model_name)
# 署名表示
for prop in onnx_model.metadata_props:
if prop.key == "signature":
print(prop.value)
# 入力名を取得
input_name = onnx_model.graph.input[0].name
# 推論対象の画像ファイルを取得
image_dir = "/home/terms/bin/pytorch-metric-learning/ROC用"
image_files = [os.path.join(image_dir, f) for f in os.listdir(image_dir) if f.endswith('.png')]
# 類似度判断の関数
def is_same_person(embedding1, embedding2):
embedding1 = cp.asarray(embedding1).flatten()
embedding2 = cp.asarray(embedding2).flatten()
cos_sim = cp.dot(embedding1, embedding2) / (cp.linalg.norm(embedding1) * cp.linalg.norm(embedding2))
return cos_sim
# 画像を読み込み、前処理を行い、モデルで推論を行う
embeddings_dict = []
i = 0
for image_file in image_files:
i += 1
# 50回に1回、CPU温度を取得
if i % 50 == 0:
# CPU温度が72度を超えていたら待機
Utils_obj.temp_sleep()
i = 0
name = os.path.splitext(os.path.basename(image_file))[0]
# nameを'_'で分割して、ラベルを取得
name = name.split('_')[0]
image = Image.open(image_file).convert('RGB')
image = transform(image)
image = image.unsqueeze(0) # バッチ次元を追加
image = image.numpy()
embedding = ort_session.run(None, {input_name: image})[0] # 'input'をinput_nameに変更
# name: embeddingの辞書を作成
dict = {name: embedding}
embeddings_dict.append(dict)
# embeddings_dictの各要素のペアを作成
pair = list(combinations(embeddings_dict, 2))
# pairのkeyが同一ならlabelを1、異なれば0とする
labels = [1 if list(pair[i][0].keys())[0] == list(pair[i][1].keys())[0] else 0 for i in range(len(pair))]
# pairの各要素の類似度を計算
scores = [is_same_person(pair[i][0][list(pair[i][0].keys())[0]], pair[i][1][list(pair[i][1].keys())[0]]) for i in range(len(pair))]
# labelsとscoresを結合
labels_scores = list(zip(labels, scores))
# Calculate accuracy, confusion matrix, precision, recall, and F1 score for different thresholds
thresholds = np.arange(0.1, 1.1, 0.01)
true_labels = [label for label, _ in labels_scores]
# 閾値ごとの結果を格納するリスト
accuracies = []
precisions = []
recalls = []
f1_scores = []
for threshold in tqdm(thresholds):
predicted_labels = [1 if score > threshold else 0 for _, score in labels_scores]
accuracy = accuracy_score(true_labels, predicted_labels)
accuracies.append(accuracy)
# Calculate confusion matrix
cm = confusion_matrix(true_labels, predicted_labels)
# Calculate precision
precision = precision_score(true_labels, predicted_labels)
precisions.append(precision)
# Calculate recall
recall = recall_score(true_labels, predicted_labels)
recalls.append(recall)
# Calculate F1 score
f1 = f1_score(true_labels, predicted_labels)
f1_scores.append(f1)
# 結果をグラフ化
plt.plot(thresholds, accuracies, label='Accuracy')
plt.plot(thresholds, precisions, label='Precision')
plt.plot(thresholds, recalls, label='Recall')
plt.plot(thresholds, f1_scores, label='F1 Score')
plt.xlabel('Threshold')
plt.ylabel('Value')
plt.title('JAPANESE FACE F1score, etc.')
plt.legend()
plt.grid(True)
plt.show()考察・まとめ
Dlibの顔学習モデルであるdlib_face_recognition_resnet_model_v1.datは、非常に高い精度を持っています。しかし、若年日本人女性の顔画像に対しては、精度が低下します。これは、Dlibの顔学習モデルが、face scrub datasetやVGGデータセットを主に使用しているところが原因と考えられます。これらのデータセットには、若年日本人女性の顔画像がほとんど含まれていないため、若年日本人女性の顔画像に対しては、性能が低下すると考えられます。
この問題を解決するため、独自の日本人顔データセットを用いて学習したモデルがJAPANESE FACEです。このモデルは、Dlibの学習モデルと同等の性能を示し、若年日本人女性の顔画像に対しては、Dlibの学習モデルよりも高い精度を示します。この学習モデルはFACE01_trained_modelsからダウンロードできます。

