
2023年版 顔認証を使った「顔が似てる芸能人ランキング」
1294人の芸能人の顔データを使って、芸能人(と著名人)の似ている組み合わせ(なんと15億8600通り以上!)を、日本人専用のAI顔学習モデル「JAPANESE FACE」を使用したプログラムを書いて検証しました。最初に結論を載せて、後半にソースコードとその説明、最後に目的を解説します。

検証結果
同一人物の違う写真がある場合、当たり前ですが本人同士がマッチしてしまいます。ここでは強制的に「他人どうし」になるように調整してあります。
またランキングは、上位に同じ人物の組み合わせがある場合、それを飛ばします。
「実はこのふたり、いとこなんです」って言われたら納得してしまうかもしれません。(実際は違いますが…)
※重要!
同一人物と判定されるためには、99%以上の値が必要です。
98%だと、別人と判定されます。

でも98.5%を超えると、「とても似ている!」っていえるよね!
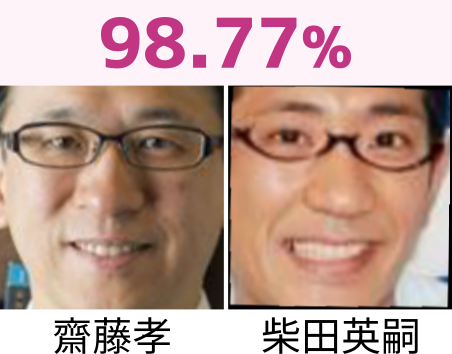
1 位 齋藤孝 柴田英嗣 98.77 %
似てますね!ご兄弟、と言われても信じてしまいそう。


2 位 近藤正臣 橋爪功 98.62 %
一瞬の陰影で、同じ人物に見えてしまいます。


3 位 今井翼 滝沢秀明 98.52 %
年齢をあわせると、そっくりですね!


4 位 片寄涼太 賀来賢人 98.51 %
兄弟、またはいとこと言われても否定できません。


5 位 宮本茉由 玉田志織 98.35 %
私がフォルダー分けを失敗したのでしょうか、と思うくらい同一人物に見えます。そっくりです。


6 位 佐藤真知子 溝口恵 98.25 %
別人と分かるのですが、パーツそれぞれはそっくりですね。


7 位 森田健作 山内健司 98.20 %
森田健作さんの写真がボケてしまっているので、判断が難しいところです。


8 位 福本清三 間寛平 98.17 %
別人と分かりますが、なんというか、似てますね!


平均顔ではどうなるか
前半は「一瞬を切り取った写真」どうしで比較しました。この場合、顔の角度や表情、陰影の影響で、たまたま似てしまうことも多々あります。
そこで、平均顔を比べ、検証してみましょう。
【平均顔について】
平均顔とは、主に心理学で用いる画像の1種です。
複数の顔画像を重ね合わせ、顔の特徴を抽出します。

結論
結論を先に書くと、98.5%を下回る結果になりました。「とても似ている」とは言い難いのですが、とりあえず見ていきましょう。
1 位 宮本茉由 玉田志織 98.35 %
かろうじて「似ているかも」といえるでしょうか。


2 位 橋爪功 近藤正臣 98.27 %
パーツの配置が似ている感じがします。


2 位 横山智佐 熊切あさ美 98.27%


4 位 山﨑努 金田明夫 98.17 %


5 位 岡本圭人 片寄涼太 98.09 %
98.09%と、決して似ているとは言い難い数値ではあるのですが、似てますね。


6 位 柴田英嗣 齋藤孝 97.83 %
記事前半で、1位をとった組み合わせです。平均顔になると97.83%まで落ちてしまいました。しかし、面影は似てます。


7 位 今井翼 滝沢秀明 97.82 %
記事前半で3位だった組み合わせですね。やはり全ての年代を総合してしまうと、そこまで似ていない、という結果になりました。


ソースコードと解説
ここからは技術的なお話です。
使用された全ての顔データセットは、「JAPANESE FACE」学習モデルの訓練には使われていません。
記事冒頭で、顔同士の組み合わせが15億8600通りある、と書きました。
以下にプログラムで走らせているとはいえ、総当り計算法では7800時間かかる計算になります。およそ1年かかる、というわけです。
そこでMeta(旧Facebook)が開発したFAISSを用います。最終的に1年かかる処理を、たった9秒にできました。

FAISS (Facebook AI類似性検索) は、開発者が互いに類似しているマルチメディア ドキュメントの埋め込みを迅速に検索できるようにするライブラリです。ハッシュベースの検索に最適化された従来のクエリ検索エンジンの制限を解決し、よりスケーラブルな類似検索機能を提供します。
FAISS
深層学習におけるモデル学習において、データセットのクレンジングは重要な作業です。
顔認証システムにおいてのデータセットのクレンジングとは、「人物Aの顔画像ファイルが、間違いなく人物Aのフォルダーに存在しているか」と定義できます。
このクレンジング作業は、ある程度自動化していますが、最終的には目視で確認する必要があります。
なかには知っている人物もありますが、大部分は知らない人物です。
スクレイピング対象の人物名がマイナーな場合(仮に人物Aとします)、同じ名字の有名人(人物B)がヒットしてしまうこともあります。
有名人と言っても私は知らないので、顔画像枚数の多い人物Bを、人物Aのフォルダーに配置してしまうかもしれません。
人物Aのフォルダーには人物Aの顔画像ファイルが存在し、人物Bのフォルダーにも人物Aの顔画像ファイルが存在することになってしまいます。
この状態は、モデル学習において、大きな悪影響を及ぼします。
そこで既存の顔学習モデルを使用して、各フォルダーの顔画像ファイルと、他のフォルダーに存在する顔画像ファイルとのコサイン類似度を計算し、類似度が高いものを抽出します。
ソースコード
import os
import time
import faiss
import numpy as np
# 処理開始時刻を記録
start_time = time.time()
# FAISSインデックスの設定
dimension = 512 # ベクトルの次元数
nlist = 100 # クラスタ数
# 量子化器を作成(内積を使用)
quantizer = faiss.IndexFlatIP(dimension)
# IVFフラットインデックスを作成
index = faiss.IndexIVFFlat(quantizer, dimension, nlist, faiss.METRIC_INNER_PRODUCT)
# データのルートディレクトリ
root_dir = "/media/terms/2TB_Movie/face_data_backup/data"
# カレントディレクトリを変更
os.chdir(root_dir)
# サブディレクトリのリストを作成
sub_dir_path_list = [
os.path.join(root_dir, sub_dir)
for sub_dir in os.listdir(root_dir)
if os.path.isdir(os.path.join(root_dir, sub_dir))
]
# データ格納用のリスト
all_model_data = []
all_name_list = []
all_dir_list = [] # ディレクトリ情報も保存
# 各サブディレクトリからデータを読み込む
for dir in sub_dir_path_list:
npz_file = os.path.join(dir, "npKnown.npz")
with np.load(npz_file) as data:
model_data = data['efficientnetv2_arcface']
name_list = data['name']
# データの形状を変更し、L2正規化を行う
model_data = model_data.reshape((model_data.shape[0], -1))
faiss.normalize_L2(model_data)
# データをリストに追加
all_model_data.append(model_data)
all_name_list.extend(name_list)
all_dir_list.extend([dir] * len(name_list))
# データをnumpy配列に変換
all_model_data = np.vstack(all_model_data)
# 量子化器を訓練し、データを追加
index.train(all_model_data)
index.add(all_model_data)
# 類似度が高い要素を検索
k = 10
D, I = index.search(all_model_data, k)
# 結果を保存
processed_pairs = set() # 既に処理されたペアを保存するセット
with open("output.csv", "a") as f:
for i in range(D.shape[0]):
for j in range(D.shape[1]):
# ペアをアルファベット順にソートしてタプルとして保存
sorted_pair = tuple(sorted([all_name_list[i], all_name_list[I[i, j]]]))
# コサイン類似度が0.7以上で、同じディレクトリでない場合、かつ、まだ処理されていないペアの場合に出力
if D[i, j] >= 0.7 and all_dir_list[i] != all_dir_list[I[i, j]] and sorted_pair not in processed_pairs:
f.write(f"{all_name_list[i]},{all_name_list[I[i, j]]},{D[i, j]}\n")
processed_pairs.add(sorted_pair) # ペアを処理済みとしてセットに追加
# 処理時間を計算して出力
end_time = time.time()
elapsed_time = end_time - start_time
minutes, seconds = divmod(elapsed_time, 60)
print(f"処理時間: {int(minutes)}分 {seconds:.2f}秒")
ソースコード解説
以下のzennにて、詳細な解説をしています。ぜひご覧ください。

最後に
いかがだったでしょうか。
今回の検証実験は一見興味本位の様に見えますが目的がしっかりとあります。顔サンプル中に顔距離の小さい顔どうしがあった場合、映像データのクオリティや表情によっては誤検出が発生します。似た顔を予め把握して対策をとることは顔認証に於いて非常に重要な前処理です。あまりにも顔距離が近い場合、サンプルとなる顔データをとりなおしたり、機械学習にかけて分類する必要があるかもしれません。
以上です。最後までお読み頂きありがとうございました。

