
顔認証が顔を識別する仕組み
顔認証がどのようにして個別の顔を判別しているのかについてざっくりとご紹介します。

目次
顔検出および認識プロセス
顔検出
カメラで撮影された映像を顔認識するプロセスは、まず映像をフレームごとに分解し、それらを数値データに変換することから始まります。そして、個々のフレームで顔が存在するかどうかを見つけるため、特定の顔検出器が利用されます。
ここで、顔検出器として用いる手法にはいくつか選択肢があります。
一つはdlibというライブラリで、これは’HOG’(Histogram of Oriented Gradients)や’CNN’(Convolutional Neural Network)の二つの方式を提供します。もう一つはmediapipeというツールで、これも顔検出に活用可能です。
これらの中から適切な検出器を選ぶための基準も存在します。例えば、大人数の中から複数の顔を見つける場合や、マスクを付けている顔を検出する場合は、’CNN’方式の顔検出器が推奨されます。ただし、この方式を活用するためには高速なCPUと高速なNVIDIA製グラフィックカードが推奨されます。
顔認識
次に、顔が検出されたらその顔の特徴を抽出するステップに移ります。
この際にはdlibの汎用顔学習モデルや、日本人専用にファインチューニングされたAI顔学習モデル「JAPANESE FACE」から選択が可能です。
ここでも比較基準が異なります。汎用顔学習モデルを用いた場合、特徴ベクトルとデータベース内の全顔エントリをユークリッド距離で相互参照します。一方、「JAPANESE FACE」を使用すると、コサイン類似度によって特徴ベクトルと全顔エントリを比較します。
これらの多様な動作は、専用の設定ファイルによって一元的に管理することが可能です。
また、様々な状況に対応できるよう、複数の設定を保持し、必要に応じて利用することもできます。
顔の比較
汎用顔学習モデルを使用する場合
ユークリッド距離の計算後、アルゴリズムは未知のタイプの人物の新しい personID を生成するか(距離が閾値より大きい場合)、顔を分類済みとしてマークし、personID と一致させます(距離が閾値より小さい場合)。
様々な顔画像に対して ResNet と呼ばれるアルゴリズムの深層学習(ディープラーニング)を介し 128 次元の特徴ベクトルの距離が同一人物で最小になるように学習してあります。ですので、同じ人物かどうかは各顔画像のベクトル間の距離を測り、閾値より小さくなるかどうかを計算することで実現します。
下の図は triplet training の代表的なよく使われる画像です。3枚の画像を1セットにし、その中の一つの画像(Query)と似ている方を Positive、似ていない方を Negative という風に3枚ごとにラベル付けを行うトレーニングです。ちなみに Chad Smith はバンドのドラマー、Will Ferrell はコメディアンで、この二人はとても似ていると評判なので例としては最適です。下の図の学習では2つの Will Ferrell の画像の測定値がより近く、Chad Smith の測定値がより遠くなるように、ニューラルネットをわずかに微調整しています。
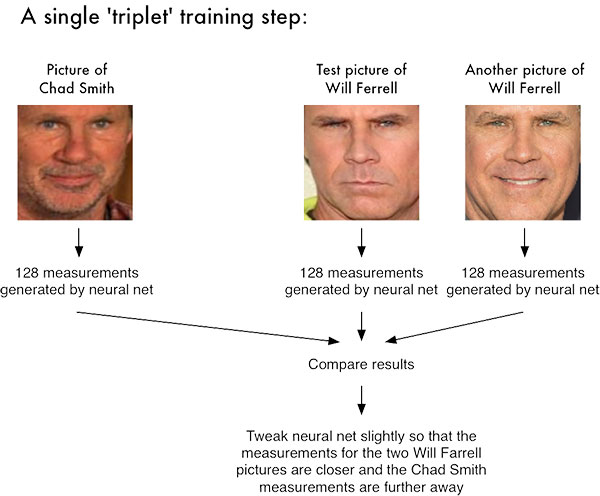
ネットワーク自体は、約 300 万枚の画像のデータセットにてトレーニングされました。 Labeled Faces in the Wild(LFW)データセットでは、ネットワークは他の最先端の方法と比較して、 99.38%の精度に達します 。ただしこの数値は外国人(特に白人)に対してのものであり、日本人に対しては精度が落ちることに注意が必要です。

顔全体の特徴を利用しますので、メガネの有無・髪型の変化など「局所的な変化」に強いのが特長です。
日本人専用にファインチューニングされたAI顔学習モデル「JAPANESE FACE」を使用する場合
私たちが開発したモデルは、EfficientNetV2-SネットワークとArcface損失関数を活用しており、日本人の顔だけを用いて学習させています。このモデルは、512次元の特徴ベクトルを出力し、この特徴ベクトルの間のコサイン類似度を計算し、顔の類似度を判断します。
EfficientNetというのは非常に効率的なネットワークで、その進化版であるEfficientNetV2はさらに効率的な推論を可能にします。さらに、Arcface損失関数の採用により、各特徴ベクトルは超球面上の角度として表現されます。これはdlibで使用しているResNet + Triplet Lossよりも洗練されており、新たな最先端技術(SOTA)を達成しています。
通常、顔認証用の学習モデルは、多種多様な人種の大量の顔画像をデータセットとして使用します。公開されているデータセットは日々進化していますが、日本人だけのデータセットは存在しないのが現状です。そこで私たちは日本人だけのデータセットを自ら作成し、さらにそのノイズを可能な限り低減しました。このようにして作成したデータセットを用いて学習したモデルは、若年日本人女性の顔識別における偽陽性」という問題を解決しています。これは、従来のdlibの学習モデルが抱えていた課題でした。
- EfficientNetV2: Smaller Models and Faster Training
- ArcFace: Additive Angular Margin Loss for DeepFace Recognition
FACE01内処理
顔登録用フォルダに集められたファイルは処理前に全て読み込まれます。この時人物名であるファイル名とベクトルデータはセットとしてnpKnown.npz圧縮バイナリデータとして保存されます。また新たに追加された場合はその追加された分のみを処理してデータが追加されます。
FACE01にはあらかじめ豊富なEXAMPLEが用意されています。その中のうち日本人専用のAI顔学習モデル「JAPANESE FACE」を使用したものを下に転載します。
"""License for the Code.
Copyright Owner: Yoshitsugu Kesamaru
Please refer to the separate license file for the license of the code.
"""
"""Example of GUI display and face recognition data output with efficientnetv2_arcface.onnx model.
Summary:
In this example you can learn how to display GUI and output
face recognition.
PySimpleGUI is used for GUI display.
See below for how to use `PySimpleGUI. <https://www.pysimplegui.org/en/latest/>`_
Example:
.. code-block:: bash
python3 example/display_GUI_window_efficientnetv2_arcface.py
Source code:
`display_GUI_window_efficientnetv2_arcface.py <../example/display_GUI_window_efficientnetv2_arcface.py>`_
"""
# Operate directory: Common to all examples
import os.path
import sys
dir: str = os.path.dirname(__file__)
parent_dir, _ = os.path.split(dir)
sys.path.append(parent_dir)
from typing import Dict
import cv2
import PySimpleGUI as sg
from face01lib.Core import Core
from face01lib.Initialize import Initialize
def main(exec_times: int = 50) -> None:
"""Display window.
Args:
exec_times (int, optional): Receive value of number which is processed. Defaults to 50 times.
Returns:
None
"""
# Initialize
CONFIG: Dict = Initialize('EFFICIENTNETV2_ARCFACE_MODEL_GUI').initialize()
# CONFIG: Dict = Initialize('DISPLAY_GUI').initialize()
# Make PySimpleGUI layout
sg.theme('LightGray')
layout = [
[sg.Image(filename='', key='display', pad=(0,0))],
[sg.Button('terminate', key='terminate', pad=(0,10), expand_x=True)]
]
window = sg.Window(
'FACE01 example with EfficientNetV2 ArcFace model',
layout, alpha_channel = 1,
margins=(10, 10),
location=(0, 0),
modal = True,
titlebar_icon="./images/g1320.png",
icon="./images/g1320.png"
)
# Make generator
gen = Core().common_process(CONFIG)
# Repeat 'exec_times' times
for i in range(0, exec_times):
# Call __next__() from the generator object
frame_datas_array = gen.__next__()
event, _ = window.read(timeout = 1)
if event == sg.WIN_CLOSED:
print("The window was closed manually")
break
for frame_datas in frame_datas_array:
for person_data in frame_datas['person_data_list']:
if not person_data['name'] == 'Unknown':
print(
person_data['name'], "\n",
"\t", "similarity\t\t", person_data['percentage_and_symbol'], "\n",
"\t", "coordinate\t\t", person_data['location'], "\n",
"\t", "time\t\t\t", person_data['date'], "\n",
"\t", "output\t\t\t", person_data['pict'], "\n",
"-------\n"
)
imgbytes = cv2.imencode(".png", frame_datas['img'])[1].tobytes()
window["display"].update(data = imgbytes)
if event =='terminate':
break
window.close()
if __name__ == '__main__':
main(exec_times = 200)
以上です。
最後までお読み頂きありがとうございました。
