
Fixed AdaCosのすすめ:固定スケールで使おう!

目次
はじめに
皆さん、損失関数は何を使ってらっしゃいますか?
不良品検出、顔認証などopen set recognition problemが絡むタスクでは、ArcFaceがよく使われている印象を受けます。
でも、ArcFaceにはスケールファクターとマージンのハイパーパラメーターがあり、煩雑です。AdaCosの論文に載っている固定スケールファクターを使えば、少なくともスケーリングファクターを調整する必要はなくなります。
しかし、Fixed AdaCosの精度と処理時間は、どんな感じなんでしょう。
そこで実際に実装して、試してみました。
結論
AdaCosを固定スケールで使うと、同等の処理時間でArcFaceよりも高い精度が出ました。
| Loss Function | Training Accuracy (%) | Test Accuracy (%) | Test Loss |
|---|---|---|---|
| ArcFace | 98.61 | 85.22 | N/A |
| AdaCos | 99.42 | 90.02 | N/A |
| CrossEntropy | 94.57 | 89.44 | 0.022136613415579192 |
- dataset
- 16 directories, 2602 files
背景
ハイパーパラメーター
経験と勘がすべてを支配する「ハイパーパラメーター指定」。これは、機械学習において、避けて通りたい作業です。
ハイパーパラメーターの調整は、勘を外せばモデルの訓練が不安定になり、精度にも悪影響がでます。
自動調整するライブラリもあるにはありますが、時間もかかりますし、パラメーター範囲の指定も必要です。
ハイパーパラメーターフリー、かつ高性能ときいて
「AdaCosはハイパーパラメーターフリーで、訓練過程で自動的にスケールパラメーターを調整できるだけでなく、高い顔認識精度を達成することが可能」、とききました。
そんな美味しい話があるんですね。
そこで早速、AdaCosを実装してtrainを回してみました。
しかし、なかなか精度が上がりません。どうしてだ。
そんな時は、論文を読むしかありません。
下のグラフを見てください。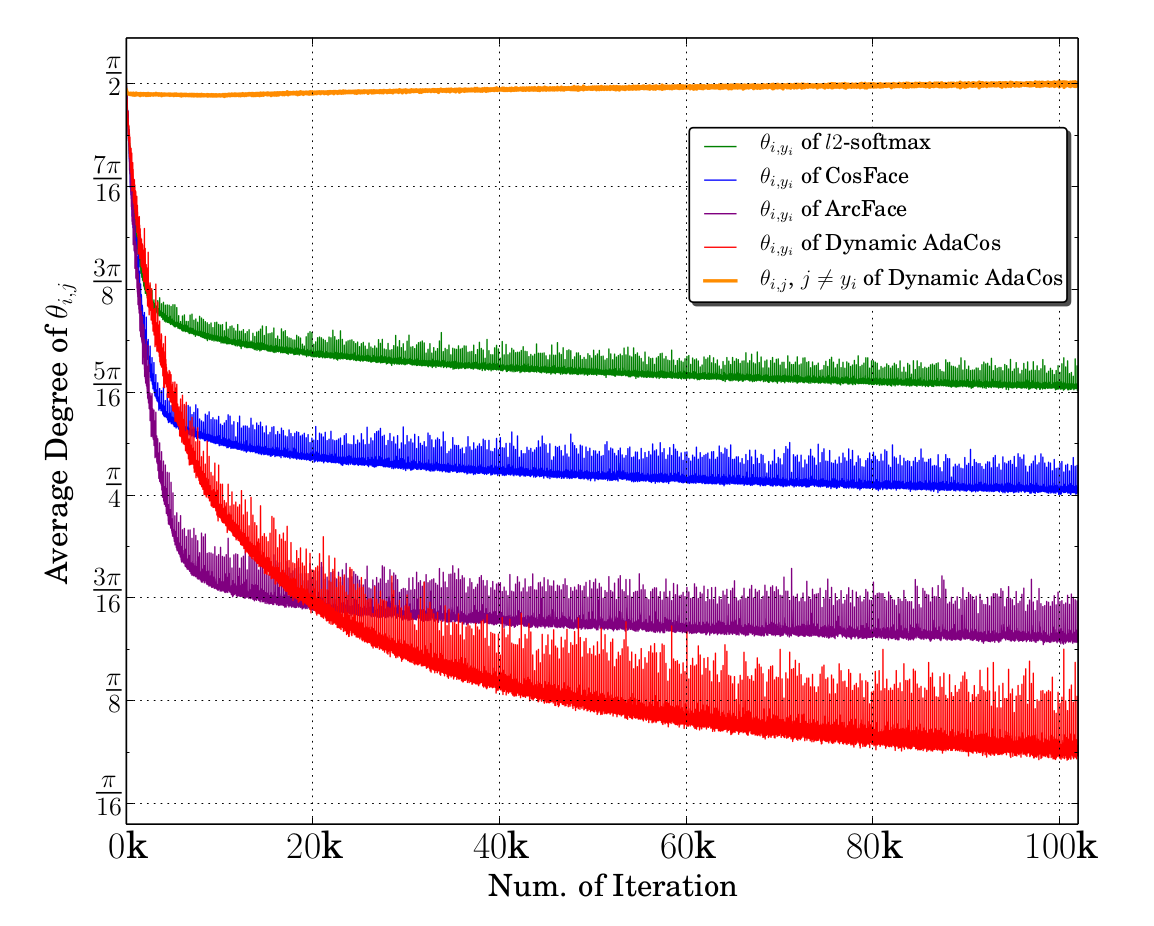
このグラフを見ると、AdaCosにおいて、同じクラスのコサイン類似度は大きく、逆に異なるクラスのコサイン類似度がグラフ中もっとも小さいことがわかります。
注目すべきは横軸です。ArcFaceよりAdaCosが優れた値を示すのは、2万epoch以降です。
いや、横軸がepochとは書いてません。ミニバッチかもしれない。それでもエグい数字です。
これだったらArcFaceの方がお手軽ではないかと思いました。
というわけで解散!…でもいいんですけど、AdaCosの論文には「固定スケーリングファクター」なるものも紹介されています。それを試してみてからでも遅くはありません。
疑問
- 固定スケール
AdaCos(Fixed AdaCos)の、イテレーションにおける縦軸がどこにも書いてない。
- 固定スケールファクターならば、
ArcFaceと同じepoch数でいけるんじゃないか?
Fixed AdaCos
論文より。
$$\tilde{s}_f = \sqrt{2} \cdot \log(C – 1)$$
クラス数が $16$ だとすると、 $約3.829$ 。
実装
2パターンを用意しました。
loss_test.py- dataset
- MNIST
- 手書き数字の10クラス分類問題。やさしい。
- model
- 独自実装
- 10 epoch
- 損失関数比較
ArcFace:regularizers.CenterInvariantRegularizer()で正規化Simple_ArcFace:ArcFaceのみFixed AdaCoss: スケーリングファクターを固定Cross Entropy: クロスエントロピーロス
loss_test_face_recognition.py- dataset
- 16 directories, 2602 face image files
- 16クラスの顔認証問題。比較的難しい。
- model
- EfficientNetV2-b0
- 10 epoch
- 損失関数比較
ArcFace:regularizers.RegularFaceRegularizer()で正規化Simple_ArcFace:ArcFaceのみFixed AdaCoss: スケーリングファクターを固定Cross Entropy: クロスエントロピーロス
| Script Name | Dataset Description | Model | Epochs | Loss Function Description |
|---|---|---|---|---|
loss_test.py | MNIST (10-class, Easy) | Custom | 10 | ArcFace with regularizers.CenterInvariantRegularizer(), Simple_ArcFace, Fixed AdaCos, Cross Entropy |
loss_test_face_recognition.py | 16 dirs, 2602 face images (16-class, Hard) | EfficientNetV2-b0 | 10 | ArcFace with regularizers.RegularFaceRegularizer(), Simple_ArcFace, Fixed AdaCos, Cross Entropy |
loss_test.py
import math
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from pytorch_metric_learning import losses, regularizers, samplers
from sklearn.neighbors import KNeighborsClassifier
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
# ハイパーパラメータの設定
epoch = 10
arcface_s = 64.0
arcface_m = 28.6
num_classes = 10
batch_size = 128
embedding_size = 128
lr = 0.01
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(1, 32, kernel_size=3) # 畳み込み層1
self.conv2 = nn.Conv2d(32, 64, kernel_size=3) # 畳み込み層2
self.fc1 = nn.Linear(64 * 12 * 12, 128) # 全結合層1
self.fc2 = nn.Linear(128, embedding_size) # 全結合層2(出力層)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.relu(x)
x = nn.functional.max_pool2d(x, 2)
x = nn.functional.dropout(x, 0.25, training=self.training)
x = x.view(-1, 64 * 12 * 12)
x = self.fc1(x)
x = nn.functional.relu(x)
x = nn.functional.dropout(x, 0.5, training=self.training)
x = self.fc2(x)
return x
class AdaCosLoss(nn.Module):
def __init__(self, num_features, num_classes=num_classes, m=arcface_m):
super(AdaCosLoss, self).__init__()
self.num_classes = num_classes # クラス数
self.s = math.sqrt(2) * math.log(num_classes - 1) # 固定値のスケーリングファクター
self.m = m # マージンmを設定
self.ce_loss = nn.CrossEntropyLoss() # 交差エントロピー損失
device = 'cuda' if torch.cuda.is_available() else 'cpu' # デバイスを確認
self.W = nn.Parameter(torch.FloatTensor(num_classes, num_features).to(device)) # self.Wを適切なデバイスに配置
nn.init.xavier_normal_(self.W) # 重みの初期化
def forward(self, logits, labels):
# logitsをL2正規化
logits = F.normalize(logits, p=2, dim=-1) # L2正規化
# 重みベクトルをL2正規化
W = F.normalize(self.W, p=2, dim=-1) # L2正規化
# コサイン類似度の計算
cos_theta = logits @ W.T # 内積でコサイン類似度を計算
# マージンmを適用
phi = cos_theta + self.m # マージンmを適用
# print(f"AdaCos cos_theta: {cos_theta}, phi: {phi}") # デバッグ情報を出力
return self.ce_loss(self.s * phi, labels) # スケーリングファクターとマージンを適用して損失を計算
class Simple_ArcFaceLoss(nn.Module):
def __init__(self, num_features, num_classes=num_classes, s=arcface_s, m=arcface_m):
super(Simple_ArcFaceLoss, self).__init__()
self.s = s
self.m = m
device = 'cuda' if torch.cuda.is_available() else 'cpu' # デバイスを確認
self.W = nn.Parameter(torch.FloatTensor(num_classes, num_features).to(device)) # self.Wを適切なデバイスに配置
nn.init.xavier_normal_(self.W)
def forward(self, logits, labels):
logits = F.normalize(logits, p=2, dim=-1)
W = F.normalize(self.W, p=2, dim=-1)
cos_theta = logits @ W.T
device = 'cuda' if torch.cuda.is_available() else 'cpu' # デバイスを確認
one_hot = torch.zeros(cos_theta.size(), device=device) # one_hotを適切なデバイスに配置
labels = labels.to(device) # labelsも適切なデバイスに配置
one_hot.scatter_(1, labels.view(-1, 1).long(), 1)
output = cos_theta * 1.0
output -= one_hot * self.m
# print(f"ArcFace cos_theta: {cos_theta}, phi: {phi}") # デバッグ情報を出力
return F.cross_entropy(self.s * output, labels)
def train(model, loss_fn, train_loader, test_loader, epochs=epoch):
model = model.to('cuda') # モデルをGPUに移動
optimizer = optim.Adam(model.parameters(), lr=lr)
for epoch in range(epochs):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to('cuda'), target.to('cuda') # データをGPUに移動
optimizer.zero_grad()
output = model(data)
loss = loss_fn(output, target)
loss.backward()
optimizer.step()
def evaluate_with_cross_entropy(model, train_loader, test_loader, loss_fn):
model.eval() # 評価モード
model = model.to('cuda')
# 訓練データでの性能評価
correct_train = 0
with torch.no_grad():
for data, target in train_loader:
data, target = data.to('cuda'), target.to('cuda')
output = model(data)
pred = output.argmax(dim=1, keepdim=True)
correct_train += pred.eq(target.view_as(pred)).sum().item()
print(f"Training accuracy: {100. * correct_train / len(train_loader.dataset)}%")
# テストデータでの性能評価
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to('cuda'), target.to('cuda') # データをGPUに移動
output = model(data)
test_loss += loss_fn(output, target).item()
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print(f"Test loss: {test_loss}, Test accuracy: {100. * correct / len(test_loader.dataset)}%")
def evaluate_with_margin(loss_name, model, train_loader, test_loader):
model.eval() # 評価モード
model = model.to('cuda')
# 訓練データで特徴量を抽出
train_features = []
train_labels = []
for data, target in train_loader:
data, target = data.to('cuda'), target.to('cuda')
with torch.no_grad():
output = model(data)
train_features.append(output.cpu().numpy())
train_labels.append(target.cpu().numpy())
train_features = np.vstack(train_features)
train_labels = np.concatenate(train_labels)
# k-NNモデルの訓練
knn = KNeighborsClassifier(n_neighbors=1)
knn.fit(train_features, train_labels)
# 訓練データでの評価
correct_train = 0
total_train = 0
for data, target in train_loader:
data, target = data.to('cuda'), target.to('cuda')
with torch.no_grad():
output = model(data)
output = output.cpu().numpy()
target = target.cpu().numpy()
pred_train = knn.predict(output)
correct_train += np.sum(pred_train == target)
total_train += target.shape[0]
train_accuracy = 100. * correct_train / total_train
print(f"{loss_name}: Training accuracy: {train_accuracy}%")
# テストデータでの評価
correct = 0
total = 0
for data, target in test_loader:
data, target = data.to('cuda'), target.to('cuda')
with torch.no_grad():
output = model(data)
output = output.cpu().numpy()
target = target.cpu().numpy()
pred = knn.predict(output)
correct += np.sum(pred == target)
total += target.shape[0]
test_accuracy = 100. * correct / total
print(f"{loss_name}: Test accuracy: {test_accuracy}%")
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,)) # MNISTの平均と標準偏差
])
train_loader = DataLoader(datasets.MNIST('assets/MNIST', train=True, download=True, transform=transform), batch_size=batch_size, shuffle=True)
test_loader = DataLoader(datasets.MNIST('assets/MNIST', train=False, download=True, transform=transform), batch_size=batch_size)
# ArcFaceでの訓練
print("Training with ArcFace")
model = SimpleCNN()
R = regularizers.CenterInvariantRegularizer()
arcface_loss = losses.ArcFaceLoss(num_classes=num_classes, embedding_size=embedding_size, margin=arcface_m, scale=arcface_s, weight_regularizer=R) # ArcFaceの損失関数
train(model, arcface_loss, train_loader, test_loader, epochs=epoch)
# ArcFaceでの評価
evaluate_with_margin('arcface', model, train_loader, test_loader)
# Simple_ArcFaceでの訓練
print("Training with Simple_ArcFace")
model = SimpleCNN()
train(model, Simple_ArcFaceLoss(num_features=embedding_size, s=arcface_s, m=arcface_m), train_loader, test_loader, epochs=epoch)
# Simple_ArcFaceでの評価
evaluate_with_margin('Simple_arcface', model, train_loader, test_loader)
# AdaCosでの訓練
print("Training with AdaCos")
model = SimpleCNN()
train(model, AdaCosLoss(num_features=embedding_size), train_loader, test_loader, epochs=epoch)
# ArcFaceでの評価
evaluate_with_margin('adacos', model, train_loader, test_loader)
# CrossEntropyでの訓練
print("Training with CrossEntropy")
model = SimpleCNN()
cross_entropy_loss = nn.CrossEntropyLoss()
train(model, cross_entropy_loss, train_loader, test_loader, epochs=epoch)
# CrossEntropyでの評価
evaluate_with_cross_entropy(model, train_loader, test_loader, cross_entropy_loss)
"""
Training with ArcFace
arcface: Training accuracy: 99.90166666666667%
arcface: Test accuracy: 97.36%
Training with Simple_ArcFace
Simple_arcface: Training accuracy: 98.71833333333333%
Simple_arcface: Test accuracy: 95.78%
Training with AdaCos
adacos: Training accuracy: 99.94833333333334%
adacos: Test accuracy: 98.09%
Training with CrossEntropy
Training accuracy: 98.31833333333333%
Test loss: 0.0004521963403734844, Test accuracy: 98.17%
| Loss Function | Training Accuracy (%) | Test Accuracy (%) | Test Loss |
|----------------|-----------------------|-------------------|-------------------------|
| ArcFace | 99.90 | 97.36 | N/A |
| Simple_ArcFace | 98.72 | 95.78 | N/A |
| AdaCos | 99.95 | 98.09 | N/A |
| CrossEntropy | 98.32 | 98.17 | 0.0004521963403734844 |
"""出力結果
| Loss Function | Training Accuracy (%) | Test Accuracy (%) | Test Loss |
|---|---|---|---|
| ArcFace | 99.90 | 97.36 | N/A |
| Simple_ArcFace | 98.72 | 95.78 | N/A |
| AdaCos | 99.95 | 98.09 | N/A |
| CrossEntropy | 98.32 | 98.17 | 0.0004521963403734844 |
簡単な分類問題を、単純なネットワークで解決した場合、CrossEntropy Lossでも良い結果を残しています。
しかし、Fixed AdaCosも良いスコアです。
loss_test_face_recognition.py
import math
import matplotlib.pyplot as plt
import numpy as np
import timm
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from pytorch_metric_learning import losses, regularizers, samplers
from sklearn.neighbors import KNeighborsClassifier
from torch import nn
from torch.utils.data import DataLoader, Subset, random_split
from torchvision import datasets, transforms
from torchvision.datasets import ImageFolder
from tqdm import tqdm
# ハイパーパラメータの設定
epoch = 10
num_classes = 16
arcface_s = 64.0
arcface_m = 28.6
batch_size = 16
lr = 0.01
resolution = 224
embedding_size = 512
# EfficientNetを読み込む
class EfficientNet(nn.Module):
def __init__(self):
super(EfficientNet, self).__init__()
# self.model = timm.create_model("efficientnet_b0", pretrained=True) # EfficientNet
self.model = timm.create_model("efficientnetv2_rw_s", pretrained=True) # EfficientNetV2
num_features = self.model.classifier.in_features # `_fc`属性を使用する
# modelの最終層にembedding_size次元のembedder層を追加
self.model.classifier = nn.Linear(num_features, embedding_size)
def forward(self, x):
x = self.model(x)
return x
def train(model, loss_fn, train_loader, test_loader, epochs=epoch):
model = model.to('cuda') # モデルをGPUに移動
optimizer = optim.Adam(model.parameters(), lr=lr)
for epoch in tqdm(range(epochs), desc="Epochs"):
model.train()
correct_train = 0 # 追加; 正解数を初期化
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to('cuda'), target.to('cuda') # データをGPUに移動
optimizer.zero_grad()
output = model(data)
loss = loss_fn(output, target)
loss.backward()
optimizer.step()
class CustomSubset(Subset):
def __init__(self, subset, transform=None):
super(CustomSubset, self).__init__(subset.dataset, subset.indices)
self.transform = transform
def __getitem__(self, idx):
sample, target = self.dataset[self.indices[idx]]
if self.transform:
sample = self.transform(sample)
return sample, target
# 画像の平均値と標準偏差
mean_value = [0.485, 0.456, 0.406]
std_value = [0.229, 0.224, 0.225]
# 画像の前処理設定(訓練用)
train_transform=transforms.Compose([
transforms.Resize((resolution, resolution)), # 解像度にリサイズ
transforms.RandomHorizontalFlip(p=0.5), # 水平方向にランダムに反転
transforms.ToTensor(), # テンソルに変換
transforms.Normalize(mean=mean_value, std=std_value) # 正規化
])
# 画像の前処理設定(テスト用)
test_transform=transforms.Compose([
transforms.Resize((resolution, resolution)), # 解像度にリサイズ
transforms.ToTensor(), # テンソルに変換
transforms.Normalize(mean=mean_value, std=std_value) # 正規化
])
# DataLoaderの設定
# 元のデータセットを読み込む
dataset = ImageFolder(root='assets/face_data')
# データセットのサイズを取得
dataset_size = len(dataset)
# 訓練データとテストデータの割合を設定(8:2)
train_size = int(0.8 * dataset_size)
test_size = dataset_size - train_size
# データセットを訓練用とテスト用に分割
train_subset, test_subset = random_split(dataset, [train_size, test_size])
# transformを適用
train_dataset = CustomSubset(train_subset, transform=train_transform)
test_dataset = CustomSubset(test_subset, transform=test_transform)
# DataLoaderの設定
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True) # 訓練用
test_loader = DataLoader(test_dataset, batch_size=batch_size) # テスト用
class AdaCosLoss(nn.Module):
def __init__(self, num_features, num_classes=num_classes, m=arcface_m):
super(AdaCosLoss, self).__init__()
self.num_classes = num_classes # クラス数
self.s = math.sqrt(2) * math.log(num_classes - 1) # 固定値のスケーリングファクター
self.m = m # マージンmを設定
self.ce_loss = nn.CrossEntropyLoss() # 交差エントロピー損失
device = 'cuda' if torch.cuda.is_available() else 'cpu' # デバイスを確認
self.W = nn.Parameter(torch.FloatTensor(num_classes, num_features).to(device)) # self.Wを適切なデバイスに配置
nn.init.xavier_normal_(self.W) # 重みの初期化
def forward(self, logits, labels):
# logitsをL2正規化
logits = F.normalize(logits, p=2, dim=-1) # L2正規化
# 重みベクトルをL2正規化
W = F.normalize(self.W, p=2, dim=-1) # L2正規化
# コサイン類似度の計算
cos_theta = logits @ W.T # 内積でコサイン類似度を計算
# マージンmを適用
phi = cos_theta + self.m # マージンmを適用
# print(f"AdaCos cos_theta: {cos_theta}, phi: {phi}") # デバッグ情報を出力
return self.ce_loss(self.s * phi, labels) # スケーリングファクターとマージンを適用して損失を計算
# # DEBUG
# # ラベルとクラス名の対応関係を表示
# print("Label to class mapping:", dataset.class_to_idx)
# # DataLoaderからいくつかのサンプルを取得
# dataiter = iter(train_loader)
# images, labels = next(dataiter)
# # 画像とラベルを表示
# for i in range(4):
# plt.subplot(2,2,i+1)
# img = images[i].permute(1, 2, 0).numpy() # C,H,W -> H,W,Cに変換
# img = img * std_value + mean_value # 正規化を元に戻す
# img = img.clip(0, 1) # 0~1の範囲にクリッピング
# plt.imshow(img)
# plt.title(f'Label: {labels[i]}')
# plt.show()
def evaluate_with_cross_entropy(model, train_loader, test_loader, loss_fn):
model.eval() # 評価モード
model = model.to('cuda')
# 訓練データでの性能評価
correct_train = 0
with torch.no_grad():
for data, target in train_loader:
data, target = data.to('cuda'), target.to('cuda')
output = model(data)
pred = output.argmax(dim=1, keepdim=True)
correct_train += pred.eq(target.view_as(pred)).sum().item()
print(f"Training accuracy: {100. * correct_train / len(train_loader.dataset)}%")
# テストデータでの性能評価
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to('cuda'), target.to('cuda') # データをGPUに移動
output = model(data)
test_loss += loss_fn(output, target).item()
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print(f"Test loss: {test_loss}, Test accuracy: {100. * correct / len(test_loader.dataset)}%")
def evaluate_with_margin(loss_name, model, train_loader, test_loader):
model.eval() # 評価モード
model = model.to('cuda')
# 訓練データで特徴量を抽出
train_features = []
train_labels = []
for data, target in train_loader:
data, target = data.to('cuda'), target.to('cuda')
with torch.no_grad():
output = model(data)
train_features.append(output.cpu().numpy())
train_labels.append(target.cpu().numpy())
train_features = np.vstack(train_features)
train_labels = np.concatenate(train_labels)
# k-NNモデルの訓練
knn = KNeighborsClassifier(n_neighbors=1)
knn.fit(train_features, train_labels)
# 訓練データでの評価
correct_train = 0
total_train = 0
for data, target in train_loader:
data, target = data.to('cuda'), target.to('cuda')
with torch.no_grad():
output = model(data)
output = output.cpu().numpy()
target = target.cpu().numpy()
pred_train = knn.predict(output)
correct_train += np.sum(pred_train == target)
total_train += target.shape[0]
train_accuracy = 100. * correct_train / total_train
print(f"{loss_name}: Training accuracy: {train_accuracy}%")
# テストデータでの評価
correct = 0
total = 0
for data, target in test_loader:
data, target = data.to('cuda'), target.to('cuda')
with torch.no_grad():
output = model(data)
output = output.cpu().numpy()
target = target.cpu().numpy()
pred = knn.predict(output)
correct += np.sum(pred == target)
total += target.shape[0]
test_accuracy = 100. * correct / total
print(f"{loss_name}: Test accuracy: {test_accuracy}%")
# ArcFaceでの訓練と評価
print("Training with ArcFace")
model = EfficientNet()
R = regularizers.RegularFaceRegularizer()
arcface_loss = losses.ArcFaceLoss(num_classes=num_classes, embedding_size=embedding_size, margin=arcface_m, scale=arcface_s, weight_regularizer=R)
train(model, arcface_loss, train_loader, test_loader, epochs=epoch)
# ArcFaceでの評価
evaluate_with_margin('arcface', model, train_loader, test_loader)
# AdaCosでの訓練と評価
print("Training with AdaCos")
model = EfficientNet()
adacos_loss = AdaCosLoss(num_features=embedding_size, num_classes=num_classes, m=arcface_m)
train(model, adacos_loss, train_loader, test_loader, epochs=epoch)
# ArcFaceでの評価
evaluate_with_margin('adacos', model, train_loader, test_loader)
# CrossEntropyでの訓練
print("Training with CrossEntropy")
model = EfficientNet()
cross_entropy_loss = nn.CrossEntropyLoss()
train(model, cross_entropy_loss, train_loader, test_loader, epochs=epoch)
# CrossEntropyでの評価
evaluate_with_cross_entropy(model, train_loader, test_loader, cross_entropy_loss)
"""
Training with ArcFace
arcface: Training accuracy: 98.60643921191735%
arcface: Test accuracy: 85.22072936660268%
Training with AdaCos
adacos: Training accuracy: 99.42335415665545%
adacos: Test accuracy: 90.01919385796545%
Training with CrossEntropy
Training accuracy: 94.56991830850552%
Test loss: 0.022136613415579192, Test accuracy: 89.44337811900192%
| Loss Function | Training Accuracy (%) | Test Accuracy (%) | Test Loss |
|----------------|-----------------------|-------------------|-------------------------|
| ArcFace | 98.61 | 85.22 | N/A |
| AdaCos | 99.42 | 90.02 | N/A |
| CrossEntropy | 94.57 | 89.44 | 0.022136613415579192 |
"""出力結果
| Loss Function | Training Accuracy (%) | Test Accuracy (%) | Test Loss |
|---|---|---|---|
| ArcFace | 98.61 | 85.22 | N/A |
| AdaCos | 99.42 | 90.02 | N/A |
| CrossEntropy | 94.57 | 89.44 | 0.022136613415579192 |
open set recognition problemの場合、損失の正則化を行ったArcFaceよりも、単純な実装のFixed AdaCosのスコアが勝りました。
まとめ
AdaCosの固定スケーリングファクターは使えます。
今回は10 epoch程度の小規模な実験でしたが、実務にも役立つ知見を得られました。
以上です。ありがとうございました。
参考文献
AdaCos: Adaptively Scaling Cosine Logits for Effectively Learning Deep Face Representations

