
概略 FACE01 GRAPHICS 1.2.4
FACE01 GRAPHICSの概略を解説します。それぞれの詳しい説明は以下からご覧ください。
こちらの記事は古くなっております。
最新のドキュメントはFACE01_DEV ドキュメントをご参照ください。
【ドキュメント】オプション FACE01 GRAPHICS ver.1.2.4
【ドキュメント】オプション変数詳細 FACE01 GRAPHICS ver.1.2.5
目次
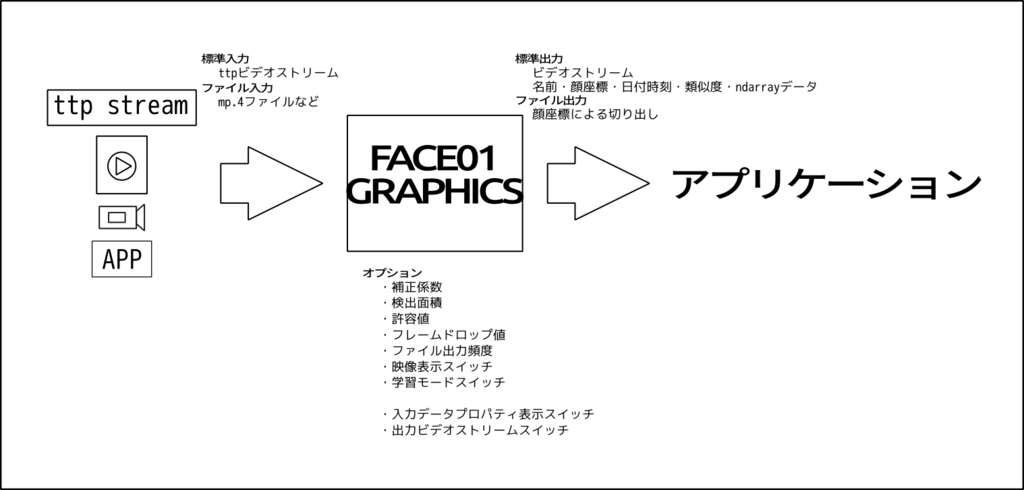
FACE01 GRAPHICS
Pythonやコマンドラインで顔検出、顔認識を行うライブラリです。オプションを指定することで様々な操作を可能にします。dlibを使用して構築されています。
デモ
無名パイプでVideo Streamを他のアプリケーションに流す例
インストール
こちらからダウンロードします。FACE01 GRAPHICSはEXEファイルとスクリプトファイルの2種類が存在します。
| メリット | デメリット | |
| EXE | Python実行環境を用意しなくて良い | CPU動作となり実行速度に劣る (GPUがある場合は高速になる可能性あり) |
| スクリプトファイル | Python実行環境を用意する必要がある | CPU動作・GPU動作を選択できる |
Windows 10、Ubuntu 18.04.5に対応しています。スクリプトファイル版にはPython実行環境が必要です。暗号化ライブラリPyArmorを使用している関係上Pythonは以下のバージョンを必要とします
- Ubuntu18.04版:Python3.6.9
- Windows10版:Python3.7.7
システム環境を汚したくない場合はpyenvを用います。詳細はこちらのページを参照して下さい。
shape_predictor_68_face_landmarks.dat
本番環境構築の際、shape_predictor_68_face_landmarks.datを東海顔認証が配布するものに差し替えることにより商用利用を可能にします。配布元のshape_predictor_68_face_landmarks.datは商用利用できません。ご注意下さい。
Python実行環境構築
EXE版には必要ありません
詳しくは以下のページをご参照下さい。
# Ubuntu版
## (必要な場合)pyenvによるPythonのバージョン合わせ
pyenv local 3.6.9
## venv仮想環境作成手順
python3 -m venv ./
## 仮想環境に入る
source ./bin/activate
## pip3アップデート
(****_UBUNTU_VENV) pip3 install -U pip ## 文末のpipはpip3ではなくpip
## pip3のバージョン確認
pip3 -V
## ライブラリ確認
(****_UBUNTU_VENV) pip3 freeze
## ライブラリ一括インストール
(****_UBUNTU_VENV) pip3 install -r requirements_FACE01_UBUNTU.txt (OR requirements_GRAPHICS_UBUNTU.txt)
## ライブラリ確認
(****_UBUNTU_VENV) pip3 freeze
# Windows版
## (必要な場合)pyenvによるPythonのバージョン合わせ
pyenv local 3.7.7
## venv仮想環境作成手順
## 仮想環境を作成する
python -m venv .\
## 仮想環境にはいる
>.\Scripts\activate
## pipアップデート
pip install -U pip
## ライブラリ一括インストール
>pip install -r requirements_LOCATION_windows.txt
## ライブラリ確認
pip freeze
## requirementsの内容
dlib
face-recognition
face-recognition-models
numpy
opencv-python
Pillow
PySimpleGUI使用方法
サンプルアプリケーションの使用方法は各々の備考欄に記載してあります。ここでは設定ファイルを用いる場合をいくつか例にとります。
設定ファイル作成
設定のためのPythonスクリプトを作成します。
最もシンプルな設定ファイルではopenCV由来のウィンドウを表示させるだけです。
# CALL_FACE01GRAPHICS_0.py
# 変数設定 ==========================
## 説明(default値)
## 閾値(0.5)
tolerance=0.45
## ゆらぎ値(0)
jitters=0
## 登録顔画像のゆらぎ値(10)
priset_face_images_jitters=10
## 最小顔検出範囲(0)
upsampling=0
## 顔検出方式(cnn)
mode='cnn'
## フレームドロップ率(-1)
frame_skip=-1
## 入力映像(test.mp4)
movie='test.mp4'
## 顔枠表示シンプル(False)
rectangle=False
## 顔枠表示標準(True)
target_rectangle=True
## 簡易ウィンドウ表示(False)
show_video=True
## 顔画像保存割合(10)
frequency_crop_image=10
## 表示エリア(NONE)
set_area='NONE'
## 収差学習<未実装>(False, 1)
face_learning_bool=False
how_many_face_learning_images=1
## 映像データ標準出力(False)
output_frame_data_bool=False
## 映像データプロパティ表示(False)
print_property=False
## 単一処理時間表示(False)
calculate_time=True
## 映像データ大きさ
SET_WIDTH=500
# ===================================
import FACE01GRAPHICS125 as fg
kaoninshoDir, priset_face_imagesDir=fg.home()
known_face_encodings, known_face_names=fg.load_priset_image.load_priset_image(
kaoninshoDir,
priset_face_imagesDir,
jitters=priset_face_images_jitters,
)
xs=fg.face_attestation(
kaoninshoDir,
known_face_encodings,
known_face_names,
tolerance=tolerance,
jitters=jitters,
upsampling=upsampling,
mode=mode,
model='small',
frame_skip=frame_skip,
movie=movie,
rectangle=rectangle,
target_rectangle=target_rectangle,
show_video=show_video,
frequency_crop_image=frequency_crop_image,
set_area=set_area,
face_learning_bool=face_learning_bool,
how_many_face_learning_images=how_many_face_learning_images,
output_frame_data=output_frame_data_bool,
print_property=print_property,
calculate_time=calculate_time,
SET_WIDTH=SET_WIDTH
)
# openCV由来のウィンドウを表示
print('停止するにはキーボードのqを押下して下さい')
for x in xs:
# <DEBUG>
if x=={}:
continue
次の設定ファイル例です。外部アプリケーションに映像データを送信します。
# CALL_FACE01GRAPHICS_1.py
import FACE01GRAPHICS124 as f
from face01lib import load_priset_image # face01libからインポート
kaoninshoDir, priset_face_imagesDir = f.home()
known_face_encodings, known_face_names = load_priset_image.load_priset_image(
kaoninshoDir,
priset_face_imagesDir,
jitters = 10,
upsampling=0,
mode='hog',
model='small'
)
# パイプ処理関連
output_frame_data_bool=True
print_property=False
xs = f.face_attestation(
kaoninshoDir,
known_face_encodings,
known_face_names,
tolerance=0.45,
jitters=0,
upsampling=0,
mode='cnn',
model='small',
frame_skip = 1,
movie="test.mp4",
rectangle='false',
target_rectangle='true',
show_video='true',
frequency_crop_image=5,
set_area='NONE',
face_learning_bool=True,
how_many_face_learning_images=1,
output_frame_data=output_frame_data_bool,
print_property=print_property
)
for x in xs:
if output_frame_data_bool==True and print_property==False:
sys.stdout.buffer.write(x['stream'].tobytes()) ## 'stream'を出力する
else:
name, pict, date, img, location, percentage_and_symbol, stream = x['name'], x['pict'], x['date'], x['img'], x['location'], x['percentage_and_symbol'], x['stream']
print(name, percentage_and_symbol, location, date)次の例ではウィンドウを表示させます。
# CALL_FACE01GRAPHICS_2.py
# 変数設定 ==========================
## 説明(default値)
## 閾値(0.5)
tolerance=0.45
## ゆらぎ値(0)
jitters=0
## 登録顔画像のゆらぎ値(10)
priset_face_images_jitters=10
## 最小顔検出範囲(0)
upsampling=0
## 顔検出方式(cnn)
mode='cnn'
## フレームドロップ率(-1)
frame_skip=-1
## 入力映像(test.mp4)
movie='some_people.mp4'
## 顔枠表示シンプル(False)
rectangle=False
## 顔枠表示標準(True)
target_rectangle=True
## 簡易ウィンドウ表示(False)
show_video=False
## 顔画像保存割合(10)
frequency_crop_image=10
## 表示エリア(NONE)
set_area='NONE'
## 収差学習<未実装>(False, 1)
face_learning_bool=False
how_many_face_learning_images=1
## 映像データ標準出力(False)
output_frame_data_bool=False
## 映像データプロパティ表示(False)
print_property=False
## 単一処理時間表示(False)
calculate_time=True
## 映像データ大きさ
SET_WIDTH=500
# ===================================
import time
from concurrent.futures import ProcessPoolExecutor
import cv2
import PySimpleGUI as sg
import FACE01GRAPHICS125 as fg
kaoninshoDir, priset_face_imagesDir=fg.home()
known_face_encodings, known_face_names=fg.load_priset_image.load_priset_image(
kaoninshoDir,
priset_face_imagesDir,
jitters=priset_face_images_jitters,
)
xs=fg.face_attestation(
kaoninshoDir,
known_face_encodings,
known_face_names,
tolerance=tolerance,
jitters=jitters,
upsampling=upsampling,
mode=mode,
model='small',
frame_skip=frame_skip,
movie=movie,
rectangle=rectangle,
target_rectangle=target_rectangle,
show_video=show_video,
frequency_crop_image=frequency_crop_image,
set_area=set_area,
face_learning_bool=face_learning_bool,
how_many_face_learning_images=how_many_face_learning_images,
output_frame_data=output_frame_data_bool,
print_property=print_property,
calculate_time=calculate_time,
SET_WIDTH=SET_WIDTH
)
# window実装
layout=[
[sg.Text('GUI実装例')],
[sg.Image(filename='', pad=(25,25), key='cam1')]
]
window=sg.Window('window1', layout, alpha_channel=1)
# 並行処理
def multi(x):
return x['img']
pool=ProcessPoolExecutor()
for x in xs:
# <DEBUG>
if x=={}:
continue
result=pool.submit(multi, x)
event, _=window.read(timeout=1)
if event == sg.WIN_CLOSED:
break
imgbytes=cv2.imencode('.png', result.result())[1].tobytes()
window['cam1'].update(data=imgbytes)
# window close
window.close()
print('終了します')
サンプルアプリケーションの引数指定に慣れていない場合SETTING MANAGERをお使いいただくことも出来ます。
顔の登録方法
priset_fase_imagesフォルダに’PNG’形式のファイルを配置して下さい。ファイル名は以下の形式に従って下さい。
名前_default.png
同一人物について2つ以上の顔を登録する場合には以下の形式に従って下さい。同一人物について登録数に上限はありません。マスクをはめた顔に対応させる場合はマスクをはめた顔もここに登録して下さい。
名前_1.png, 名前_2.png
顔は正面を向いた画像にして下さい。斜めを向いていたりうつむいた顔は避けて下さい。
極端に濃い化粧は精度を悪化させます。また眉毛が隠れるような長い前髪は避けて下さい。
可能な限り顔認証を行うカメラと登録を行うカメラを同一にして下さい。スマートフォンやコンパクトカメラの使用は精度を悪化させます。
高速化
GPU使用
良いパフォーマンスを出すにはGPUアクセラレーション(NVidiaのCUDAライブラリ経由)が必要です。またdlibをコンパイルする際にCUDAサポートを有効にする必要あります。
load_priset_image()メソッド
ver. 1.2.4からload_priset_image()メソッドにおけるmode選択が自動になりました。特に理由がない限り’hog’を指定して下さい。
jitters値指定は可能であれば大きめの値を設定して下さい。(10) データベースを構築する最初の1回目のみ時間がかかります。
face_attestation()メソッド
特に理由のない限りupsampling値を大きく設定しないで下さい。通常値: 0
GPU利用時においては’hog’よりも’cnn’の方が処理速度が高くより正確です。
複数同時認証では人数と処理時間に相関があります。
