
週刊誌取材で掲載できなかった技術的なはなし

目次
はじめに
「女性自身」を発行している光文社様から、「江口洋介さんと松村北斗さんの顔が似ているかどうか」を科学的に検証してほしいとのご依頼がありました。
これまでにも私たちは「似ている芸能人」についてブログで取り扱ったことがありますが、今回はさらに一歩進んで、顔画像の類似度を計算する原理とAIの説明可能性を提示し、その「似ている」かどうかを定量的に評価してみることにしました。
江口洋介さんといえば、「あんちゃん」のイメージが強く、はつらつとした魅力がありますね。一方の松村北斗さんも独自の魅力を持っています。しかし、お二人の年齢差を考慮すると、顔の特徴が大きく異なる可能性があり、類似度はそれほど高くないかもしれません。
そこで、光文社様から提供していただいたお二人の写真を用いて、初めての類似度計算を行いました。ただし、この記事では権利の問題から、その写真を直接使用することはできません。そのため、ここではインターネット上で公開されている写真を引用して、同様の類似度計算とその根拠の検証を行います。
類似度計算には、日本人専用に学習されたモデルを使用します。
具体的には、日本人だけのデータセットを用い、EfficientNetV2–SネットワークとArcFaceLossを組み合わせたモデルを用いています。
このモデルは、顔画像から特徴を抽出し、それらの特徴がどれだけ似ているかを計算することができます。
AIの説明可能性については、枯れた技術ともいえるGrad-CAMを用いて、顔画像のどの部分が類似度に影響を与えているかを可視化することにしました。
この記事では、紙面の都合上掲載できなかった検証結果や、検証に使用したコードを公開します。
まずEfficientNetV2とはなにか
EfficientNetV2の仕組みと使用理由
学習モデルを作成したり、Grad-CAMを実装したりと、非常に肝となる部分ですので、ここはしっかりと説明します。
2021年の論文です。
https://arxiv.org/abs/2104.00298
EfficientNetV2とは
“EfficientNetV2 is a new family of convolutional networks that have faster training speed and better parameter efficiency than previous models. We develop a new training method that uses progressive learning and a simplified version of the architecture. Our experiments show that EfficientNetV2 models train much faster than state-of-the-art models while being up to 6.8x smaller. Our best model achieves new state-of-the-art 91.7% top-1 accuracy on ImageNet.”日本語訳:
“EfficientNetV2は、以前のモデル(EfficientNet)よりも訓練速度が速く、パラメータ効率が良い新しい畳み込みネットワークのファミリーです。
我々は、プログレッシブな学習とアーキテクチャの簡略化バージョンを使用する新しい訓練方法を開発しました。
我々の実験では、EfficientNetV2モデルは最先端のモデルよりもはるかに速く訓練され、最大で6.8倍小さくなります。
我々の最良のモデルは、ImageNetで新たな最先端の91.7%のトップ1精度を達成します。”
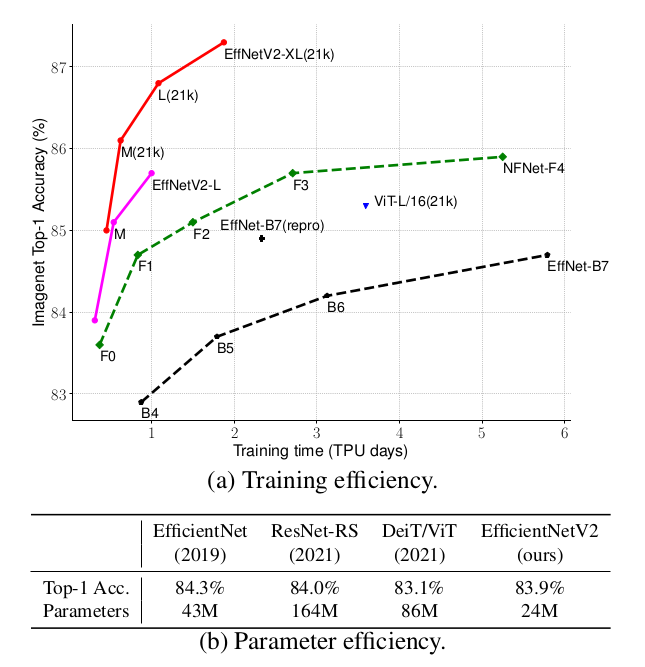
EfficientNetV2は、以前のモデルよりも高速なトレーニング速度と優れたパラメータ効率を持つ、新しい畳み込みネットワークです。
これらのモデル(S, M, L, XL)は、トレーニングに対応したニューラルアーキテクチャ検索と、スケーリングの組み合わせを使用しています。
これらは前バージョン同様、Fused-MBConv(Fused Mobile Inverted BottleNeck Convolution)などの新しいオペレーションを使った検索空間から検索(ニューラルアーキテクチャ検索(Neural Architecture Search, NAS))されました。
脱線:Fused-MBConvなどのオペレーションについて
Fused-MBConv(Fused Mobile Inverted BottleNeck Convolution)は、EfficientNetV2で使用される特定の種類の畳み込み層のことを指します。この名前は、その構造がMobileNetV2で導入されたInverted ResidualsとLinear Bottlenecksという手法を利用していることから来ています。具体的には、通常の畳み込み層では、入力特徴マップに対して畳み込みを行い、その結果を活性化関数(例えばReLU)に通して非線形性を導入し、さらに次の層への入力を生成します。しかし、Inverted ResidualsとLinear Bottlenecksを使用すると、このプロセスが少し変わります。
まず、Inverted Residualsでは、畳み込みを行う前に入力特徴マップのチャネル数を増やす(=拡張)し、次に、この拡張された特徴マップに対して、通常は1×1の畳み込みを行います。そして、その結果を活性化関数に通し、さらにチャネル数を元の数に戻すための1×1の畳み込みを行います。このとき、最後の畳み込み後には活性化関数を適用せしません。これをLinear Bottleneckと呼びます。
Fused-MBConvでは、これらの操作が一つの層に「融合(Fused)」されています。つまり、拡張、畳み込み、活性化、チャネル数の縮小という一連の操作が、一つのFused-MBConv層で一度に行われます。
論文中の「オペレーション」は、ここでは「操作」や「処理」の意味で使われています。つまり、「Fused-MBConvなどのオペレーション」とは、ネットワークがデータに対して行う、上述の特定の種類の計算や処理のことを指します。
著者らは、正則化やデータ拡張を、画像サイズとともにいい感じに調整するProgressive Learningの改善方法を提案しています。これにより、EfficientNetV2はImageNetやCIFAR/Cars/Flowersのデータセットで以前のモデルを大幅に上回りました。
同じImageNet21kで事前学習することで、EfficientNetV2はImageNet ILSVRC2012で87.3%のトップ1精度を達成し、同じ計算リソースを使用して5倍から11倍高速にトレーニングすることで、最近のViTを2.0%の精度で上回りました。
ということで、顔学習モデルには、EfficientNetV2-Sを用いています。
Progressive Learningとはなにか
論文の第4章にProgressive Learning手法が紹介されています。これは、学習の進行に応じて画像の解像度とデータ拡張を変更するというものです。
many other works dynamically change image sizes during training (Howard, 2018; Hoffer et al., 2019), but they often cause a drop in accuracy.
このように書いてあるとおり、「トレーニング中に画像サイズを動的に変更すると、精度の低下を引き起こし」ます (Howard, 2018; Hoffer et al., 2019)。
著者らはこの原因を「不均衡な正則化」にあるとしています。これを実際にあれやこれやと試したのが論文のFig.5です。
この表をじっと見つめると、対角線上に良い結果が並んでいるのが分かりますね。つまり、入力される画像解像度に応じてRandAugの値を調節するのがよさそうなのが分かります。
論文より翻訳:
Fig.4は、改善された漸進的学習のトレーニングプロセスを示しています。
初期のトレーニング エポックでは、ネットワークが単純な表現を簡単かつ迅速に学習できるように、より小さな画像と弱い正則化を使用してネットワークをトレーニングします。
次に、画像サイズを徐々に大きくしますが、より強力な正則化を追加することで学習をより困難にします。
私たちのアプローチは、画像サイズを徐々に変更する(Howard, 2018)に基づいていますが、ここでは正則化も適応的に調整します。

論文でのこのProgressive Learning with adaptive Regularizationを実装に落とし込むため、学習ループは以下のように工夫しました。
Progressive Learningの実装コード
mean_value = [0.485, 0.456, 0.406]
std_value = [0.229, 0.224, 0.225]
def resize_transform(resolution):
return transforms.Compose([
transforms.Resize((resolution, resolution)),
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomRotation(degrees=15),
transforms.RandomResizedCrop(size=(resolution, resolution), scale=(0.8, 1.0), ratio=(0.75, 1.33)),
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),
transforms.ToTensor(),
transforms.Normalize(
mean=mean_value,
std=std_value
)
])
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(
mean=mean_value,
std=std_value
)
])
for epoch in range(epoch, num_epochs):
# エポック数に応じて解像度を変更: Progressive Learningの実装
# EfficientNetV2-S
if epoch < 3:
resolution = 32
elif epoch < 6:
resolution = 64
elif epoch < 9:
resolution = 128
else:
resolution = 224
train_transform = resize_transform(resolution)論文中のProgressive learningは、この実装とは異なります。 本来なら、画像解像度と同時に、RandAugment(N=2, M=magnitude)のようにしなければなりません。
EfficientnetV2側で自動的に行われるので、この操作は必要ありません。
Grad-CAMとはなにか
Grad-CAMの仕組みと使用理由
入力されたお二人の顔画像の、どの領域を学習モデルが注視しているか。これを検証するために用いた手法です。
https://arxiv.org/pdf/1610.02391.pdf
この論文では「視覚化はクラスをより正確に識別し、分類器の信頼性をより適切に明らかにし、データセット内のバイアスを特定するのに役立つことが明らか」と主張しています。
実際、Grad-CAM(Gradient-weighted Class Activation Mapping)は、畳み込みニューラルネットワーク(CNN)の特定のクラスへの予測の視覚的説明を生成する手法として今でも有用です。
Grad-CAMは、ネットワークの最後の畳み込み層の特徴マップに対するクラスの勾配を計算します。これらの勾配(ニューロンの重要度)は、特徴マップの各チャネルに対する重みとして解釈されます。これらの重み付き特徴マップを組み合わせることで、最終的なクラス活性化マップ(CAM)が生成されます。
このCAMは、ネットワークが特定のクラスを予測する際に、どの部分(またはどのニューロン)が重要であるかを視覚的に示します。要するに、CNNが特定のクラスを予測するために「注視」している画像の領域がどの領域なのかを視覚化してくれます。
バイアスを明らかにする
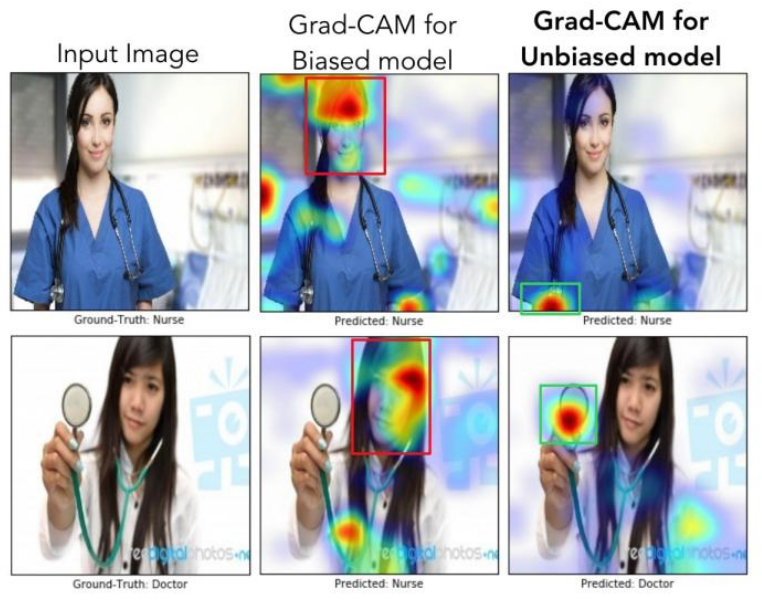
この論文では、医師と看護師を識別するための実験が行われています。
論文中で、モデルは女性の医師を看護師と誤分類し、男性の看護師を医師と誤分類していました。これは、データセットに性別によるバイアスが存在したためで、実際、データセットの医師の画像の78%が男性で、看護師の画像の93%が女性だったとのことです。
Grad-CAMを使用した結果、「モデルが人の顔や髪型を見て、看護師と医師を区別することを学習している」ことが明らかになりました(上図の真ん中の列参照)。これでは、性別のステレオタイプを学習してしまっており、問題があります。
この結果に鑑み、訓練セットのバイアスを減らすために、男性の看護師と女性の医師の画像を追加し、クラスごとの画像の数を維持した結果、再訓練されたモデルはより良く一般化されテスト精度が90%に向上しました。また、適切な領域を見ていることも確認されました(上図の右端の列)。

この実験は、Grad-CAMがデータセットのバイアスを検出し、除去するのに役立つこと、そしてそれがより良い一般化だけでなく、一般社会で認知バイアスが大きいほど、公正で倫理的な結果になるように調整しなくてはいけない事実を示す証拠となってます。
分類エラーの理由を明らかにする
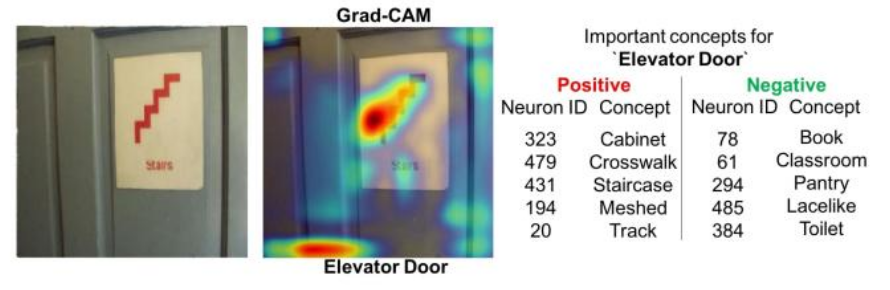
論文中の図9の(d)では、ロッカーに貼られている紙にニューロンが反応して、エレベーターと誤分類しています。この誤分類の理由を調べるために、Grad-CAMを使ってモデルがどの領域に注目しているのかを可視化しています。このように、Grad-CAMはモデルが誤分類する理由を明らかにすることができます。
さて、このGrad-CAMを使って、お二人の顔画像のどの部分にAIが注目しているのかを可視化してみましょう。
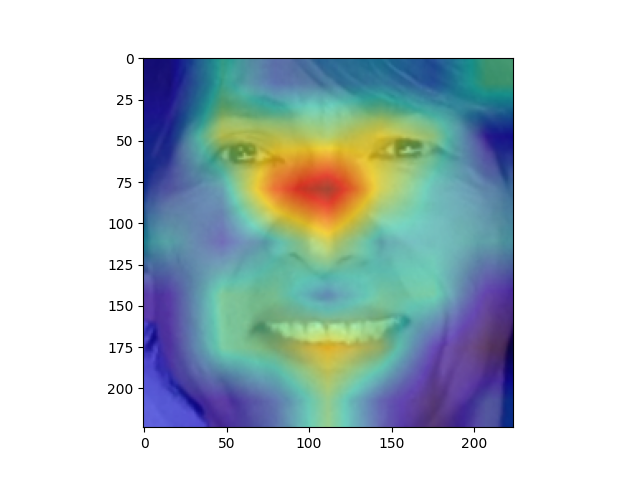
こちらは江口洋介さんの顔画像ですが、モデルは目尻から鼻筋にかけて注視しているのがみてとれます。
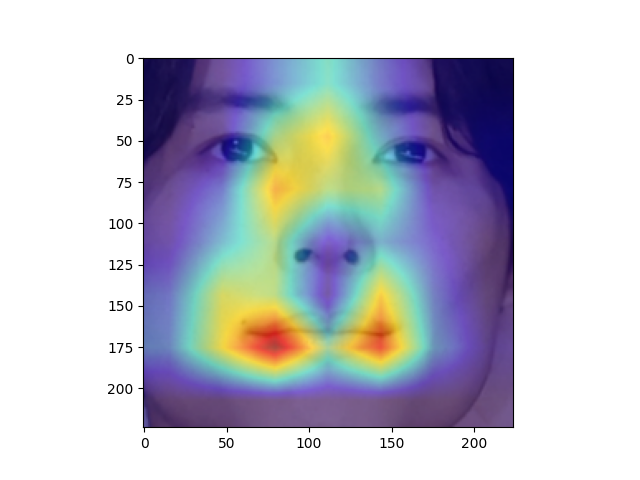
そしてこちらが植松北斗さんの顔画像です。口元から鼻筋にかけて注視しているのがみてとれます。
ここで、人間のニューロンがどのようにして画像を認識しているのかを見ていきましょう。
人間の視覚野のニューロンは、特定の視覚的特徴、つまり異なる方向の線に反応する別々の神経細胞が存在することが知られています。
垂直線、水平線、斜線に選択的に反応するニューロンが視覚情報を処理し、視覚世界の知覚に寄与する複雑な細胞のネットワークを形成しています。
人工知能研究のための視覚情報処理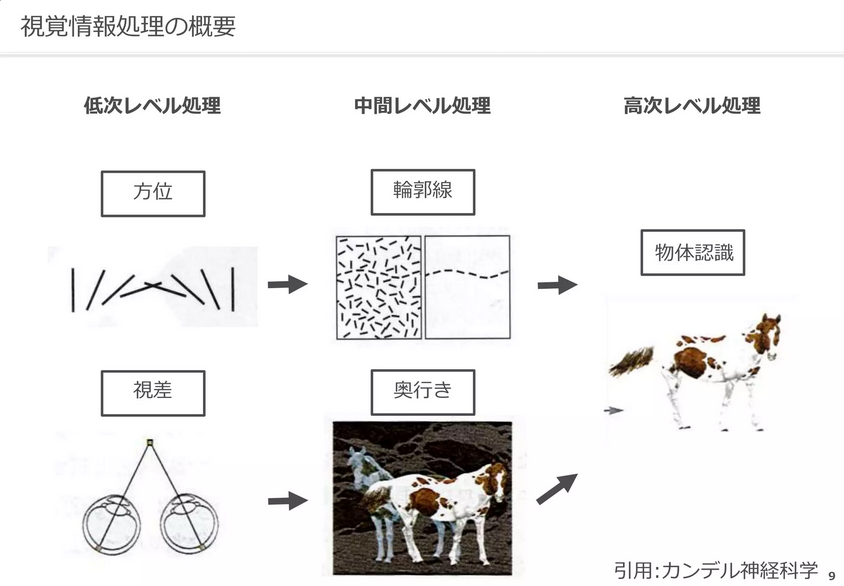
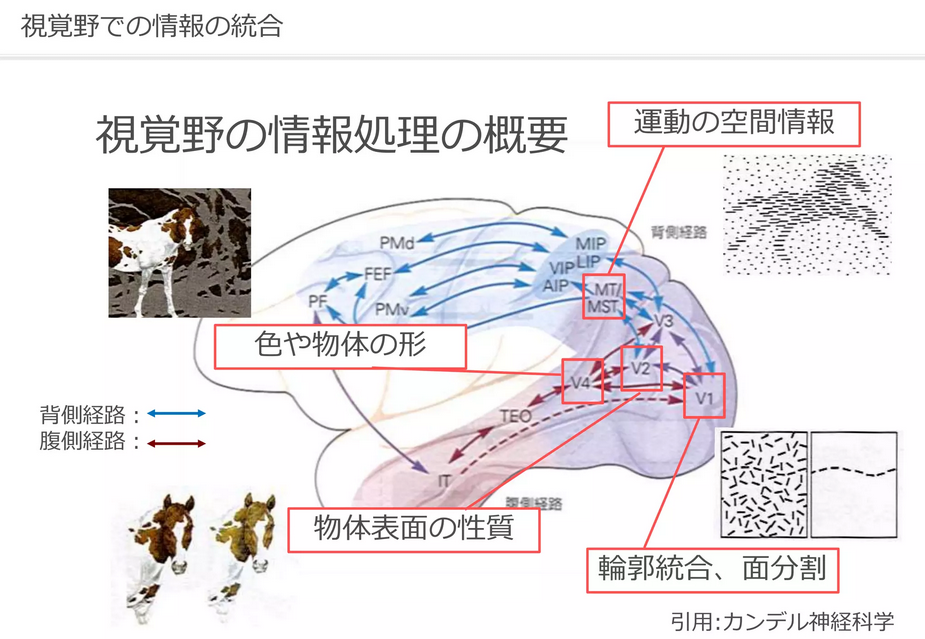
https://www.slideshare.net/KokiNakamura/ss-50460481
少し古いですが分かりやすいサーベイがこちらです。
視覚とパターン認識
https://annex.jsap.or.jp/photonics/kogaku/public/17-02-kaisetsu1.pdf
ここで、CNNの「畳み込み」の原理を思い出して下さい。人間と同じようなことを行っているということが分かります。
これは仮定の話ですが、Grad-CAMが示した「特定の顔領域に注目」している画像から、人間のニューロンもまた「特定の視覚的特徴」に反応しているのではないかと思います。自覚していないだけで、このお二人を別人と認識する際にGrad-CAMと同じような領域に注目しているのではないでしょうか。
学習モデルと人間の、双方のニューロンが同じような働きを持つことから、人間のニューロンもまた「特定の視覚的特徴」に反応しているのではないか…と仮定すると非常に面白いですね。
これは個人的な感想ですが、padding値の小さな顔画像をたくさん並べられた時、人間はこれらの顔画像を認識するのが難しいと感じています。
つまり人間は人間を、雰囲気や体格、服装など総合的に認識しているのではないかと思います。これは私達の次なる課題であり、今現在注目しているのはconformerのようなネットワークです。
Grad-CAMの実装コード
それではGrad-CAMを実際に実装してみましょう。
EfficientNet V2をベースとしたモデルを定義し、Grad-CAMの対象となる層をEfficientNet V2の最終的な畳み込み層であるself.trunk.blocks[-1]と指定しています。
import numpy as np
import torch
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
import cv2
import timm
from torch import nn
from pytorch_grad_cam import GradCAM
# モデルの定義
class CustomModel(nn.Module):
def __init__(self, embedding_dim=512):
super(CustomModel, self).__init__()
# EfficientNet V2の事前学習済みモデルを取得し、trunkとして定義
self.trunk = timm.create_model('tf_efficientnetv2_b0', pretrained=True)
num_features = self.trunk.classifier.in_features
# trunkの最終層にembedding_size次元のembedder層を追加
self.trunk.classifier = nn.Linear(num_features, embedding_dim)
def forward(self, x):
return self.trunk(x)
input_image = "hokuto.png"
# 画像の前処理を定義
mean_value = [0.485, 0.456, 0.406]
std_value = [0.229, 0.224, 0.225]
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(
mean=mean_value,
std=std_value
)
])
# モデルのインスタンスを作成
pytorch_model = CustomModel()
# モデルの状態辞書をロード
state_dict = torch.load("best_model_169epoch_512diml.pth")
# 状態辞書をモデルに適用
pytorch_model.load_state_dict(state_dict)
# モデルを評価モードに設定
pytorch_model.eval()
# Grad-CAMのための最終層を指定
target_layer = pytorch_model.trunk.blocks[-1]
# Grad-CAMのインスタンスを作成
cam = GradCAM(pytorch_model, target_layer, use_cuda=False)
# 画像の読み込みと前処理
image = Image.open(input_image)
input_tensor = transform(image) # 前処理の適用
input_tensor = input_tensor.unsqueeze(0) # バッチ次元の追加
# Grad-CAMの実行
target_category = None
grayscale_cam = cam(input_tensor, target_category)
# ヒートマップの作成
grayscale_cam = grayscale_cam[0, :]
heatmap = cv2.applyColorMap(np.uint8(grayscale_cam * 255), cv2.COLORMAP_JET)
heatmap = cv2.cvtColor(heatmap, cv2.COLOR_BGR2RGB) # 追加:ヒートマップの色の順序をRGBに変更
# 画像の読み込み
original_image = cv2.imread(input_image, cv2.IMREAD_COLOR)
original_image = cv2.cvtColor(original_image, cv2.COLOR_BGR2RGB)
# 画像とヒートマップのサイズが同じであることを確認
assert original_image.shape == heatmap.shape
# 画像とヒートマップをアルファブレンド
alpha = 0.5
blended = cv2.addWeighted(original_image, alpha, heatmap, 1 - alpha, 0)
# 結果を表示
plt.imshow(blended)
plt.show()Average face(平均顔)の作成
Average faceとはなにか
「平均顔」または「Average face」は、一連の顔画像の平均を取ることで生成される顔のイメージです。これは、一般的には、特定の集団(例えば、特定の国や地域の人々、特定の年齢層、特定の性別など)の「典型的な」顔を表現するために、主に心理学の分野で使用されます。
例えば、顔の美しさや魅力、様々な顔に対する人間の反応に関する研究でよく使われています。

操作性を考慮した顔画像合成システム: FUTON—— 顔認知研究のツールとしての評価 ——
https://search.ieice.org/data/d_data/j85-a_10_1126/10a_9.pdf

今回の記事では、「補足」という意味で、平均顔を作成してみました。
平均顔を作成するプロセスは次のように行われます:
- 顔画像収集:これらの画像は同じサイズである必要があり、顔の特徴(目、鼻、口など)が同じ位置に揃えられている必要があります。
- 各画像の各ピクセルの色値(通常はRGB値)の平均を計算:すべての画像をスタックし、各ピクセル位置での色値の平均をとります。
- 画像を生成
もし、ありふれた芸能人の平均顔と、お二人から作られた平均顔の「感覚的な距離が遠い」場合、お二人を互いに「似ている」と感じることに不思議ではないでしょう。

これは補助的な資料であり、感覚的な部分が大きいので、あまり科学的なものではありません。しかし、ふたつの平均顔は、それぞれ違うカテゴリにありそうなことは理解して頂けるのではないでしょうか。
平均顔作成の実装コード
それでは平均顔作成コードを見てみましょう。
このコードは、顔認証ライブラリFACE01のエグザンプルコードをそのまま使用しています。
import cv2
import numpy as np
import os
import glob
import mediapipe as mp
# Initializing the Mediapipe face landmark detector
mp_face_mesh = mp.solutions.face_mesh # type: ignore
face_mesh = mp_face_mesh.FaceMesh()
# Change directory where average_face.txt exists
root_dir = '/home/terms/ドキュメント/similarity_of_two_persons/tmp/mix'
os.chdir(root_dir)
def align_face(image):
# Detecting face landmarks
results = face_mesh.process(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
if results.multi_face_landmarks:
for face_landmarks in results.multi_face_landmarks:
# Calculating the center of the face
center = np.mean([[data.x, data.y] for data in face_landmarks.landmark], axis=0).astype("int")
# Calculating the angle of the face
dX = face_landmarks.landmark[33].x - face_landmarks.landmark[263].x
dY = face_landmarks.landmark[33].y - face_landmarks.landmark[263].y
angle = np.degrees(np.arctan2(dY, dX)) - 180
# Calculating the center of the image
(h, w) = image.shape[:2]
(cX, cY) = (w // 2, h // 2)
# Rotating the image to align the face frontally
M = cv2.getRotationMatrix2D((cX, cY), angle, 1.0)
aligned = cv2.warpAffine(image, M, (w, h), flags=cv2.INTER_CUBIC, borderMode=cv2.BORDER_REPLICATE)
return aligned
png_list = glob.glob(f'{root_dir}/*.png')
images = []
for png_file in png_list:
image = cv2.imread(png_file)
aligned = align_face(image)
resized = cv2.resize(aligned, (224, 224)) # type: ignore
images.append(resized)
# Converting images to a numpy array
images = np.array(images)
# Calculating the average face
average_face = np.mean(images, axis=0).astype("uint8")
# Displaying the average face
cv2.imshow("Average Face", average_face)
cv2.waitKey(0)類似度計算
それでは最終的な類似度計算を行います。
この日本人専用学習モデルでは90%以上が同一人物と認められるように閾値を設定してあります。
早速コードを見ていきましょう。こちらのコードも顔認証ライブラリFACE01のエグザンプルコードをそのまま使用しています。
import os.path
import sys
import numpy as np
dir: str = os.path.dirname(__file__)
parent_dir, _ = os.path.split(dir)
sys.path.append(parent_dir)
from typing import Dict, List
import cv2
import dlib
import numpy.typing as npt
from face01lib.api import Dlib_api
from face01lib.Initialize import Initialize
from face01lib.logger import Logger
api_obj = Dlib_api()
# Initialize
CONFIG: Dict = Initialize('EFFICIENTNETV2_ARCFACE_MODEL', 'info')._configure()
# Set up logger
logger = Logger(CONFIG['log_level']).logger(__file__, CONFIG['RootDir'])
face_path_list =[
'example/https://raw.githubusercontent.com/yKesamaru/similarity_of_two_persons/master/img/麻生太郎_default.png',
'example/https://raw.githubusercontent.com/yKesamaru/similarity_of_two_persons/master/img/安倍晋三_default.png'
]
encoding_list = []
for face_path in face_path_list:
img = dlib.load_rgb_image(face_path) # type: ignore
face_image = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
face_locations: List = api_obj.face_locations(img, mode="cnn")
face_encodings: List[npt.NDArray] = api_obj.face_encodings(
deep_learning_model=1,
resized_frame=img,
face_location_list=face_locations
)
encoding_list.append(face_encodings[0])
emb0 = encoding_list[0].flatten()
emb1 = encoding_list[1].flatten()
cos_sim = np.dot(emb0, emb1) / (np.linalg.norm(emb0) * np.linalg.norm(emb1))
percentage = api_obj.percentage(cos_sim)
print(percentage)
このコードでは麻生さんと安倍さんの顔画像の類似度を計算しています。
[2023-07-29 22:42:41,801] [face01lib.api] [api.py] [INFO] FACE01: 商用利用にはライセンスが必要です
Copyright Owner: Yoshitsugu Kesamaru
79.89結果は79.89%となりました。
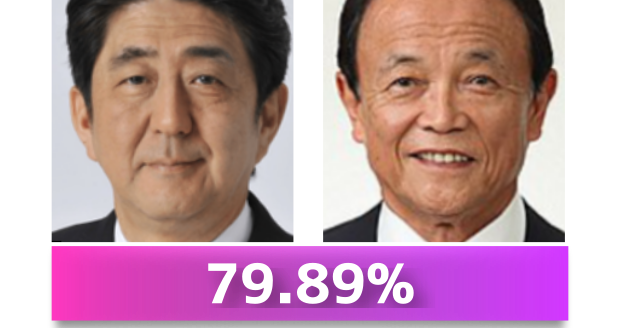
この結果は、麻生さんと安倍さんの顔画像は同一人物ではないということを意味します。
次にお二人です。
X(旧twitter)にてお写真を出されて比較されてた方がいらっしゃったので、引用させて頂きます。

さて、私がネットを見て回った中では、この写真がもっともお二人の年齢が近そうに感じました。
それではこのスクリーンショット画像をFACE01のエグザンプルコードに入力して、学習モデルが扱えるようにアライメントしましょう。
import os
import re
import subprocess
import sys
import time
import concurrent.futures
sys.path.append('/home/terms/bin/FACE01_IOT_dev')
from face01lib.utils import Utils # type: ignore
Utils_obj = Utils()
def crop_face(file_path):
print(f'file_path: {file_path}')
# CPU温度が72度を超えていたら待機
Utils_obj.temp_sleep()
Utils_obj.align_and_resize_maintain_aspect_ratio(
path=file_path,
padding=0.1,
size=224
)
# folderフォルダ内の画像ファイル(files)を削除する
print(file_path)
try:
os.remove(file_path)
except FileNotFoundError:
print(f'FileNotFoundError: {file_path}')
pass
if __name__ == '__main__':
root_path = '/home/terms/ドキュメント/similarity_of_two_persons/tmp'
crop_file_path_list:list = []
# 'align_resize'がファイル名に含まれていないファイルをリスト化する
for dir_name in os.listdir(root_path):
# align_resize_flag = False
# dir_path = os.path.join(root_path, dir_name, 'same_face') # same_faceフォルダを対象にする
dir_path = os.path.join(root_path, dir_name)
file_list = os.listdir(dir_path)
for file in file_list:
# もしfileがフォルダだったら
if os.path.isdir(os.path.join(dir_path, file)):
continue
# もしファイル名に"align_resize"が含まれていたら
elif re.search(r'align_resize', file):
continue
# もしfileの拡張子が'.webp'だったら
elif re.search(r'\.webp$', file):
web2jpg_cmd = ['convert', os.path.join(dir_path, file), os.path.join(dir_path, file.replace('.webp', '.jpg'))]
subprocess.run(web2jpg_cmd)
os.remove(os.path.join(dir_path, file))
file_path = os.path.join(dir_path, file)
crop_file_path_list.append(file_path)
if not 'align_resize' in file:
# print(file)
file_path = os.path.join(dir_path, file)
crop_file_path_list.append(file_path)
else:
print(file)
exit()
# # # 並行処理
# max_workers = 2
# with concurrent.futures.ProcessPoolExecutor(max_workers=max_workers) as executor:
# executor.map(crop_face, crop_file_path_list)
for file_path in crop_file_path_list:
crop_face(file_path)
# 終了音を鳴らす
cmd = ['play', '-q', '/home/terms/bin/face_annotation/voice/フェイスクロップ処理終了.wav']
subprocess.run(cmd)アライメントの結果、このように顔画像が出力されました。

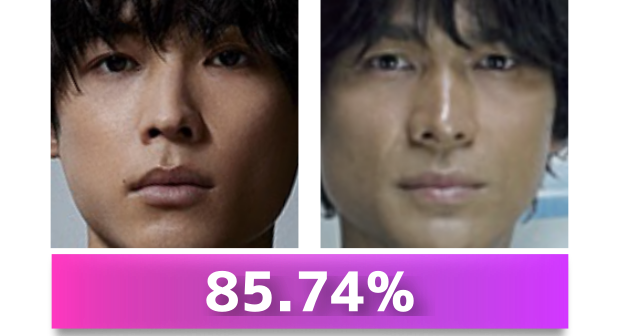
このお二人の写真を、先程の類似度計算コードに入力します。
以下が出力結果です。
[2023-07-29 22:42:41,801] [face01lib.api] [api.py] [INFO] FACE01: 商用利用にはライセンスが必要です
Copyright Owner: Yoshitsugu Kesamaru
85.7485.74%となりました。90%以上が本人と認識されますので、別人と認識されたとはいえ、かなり似ているということがわかります。
参考資料として、姉妹であられる浅田舞さんと浅田真央さんの顔画像を入力して見ましょう。

以下が出力結果です。83.06%となりました。
[2023-07-29 22:42:41,801] [face01lib.api] [api.py] [INFO] FACE01: 商用利用にはライセンスが必要です
Copyright Owner: Yoshitsugu Kesamaru
83.06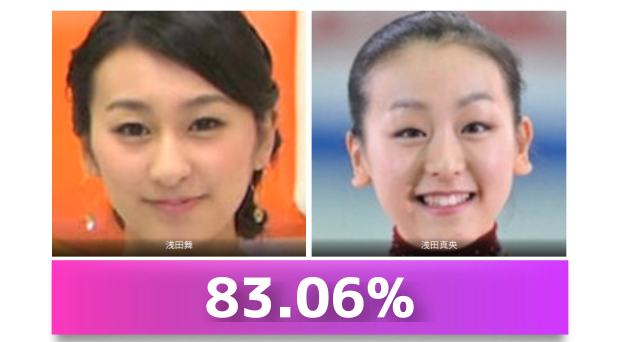
こちらは姉妹ですが、江口さん-植松さんの組み合わせより、2.64ポイントも低くなりました。
あとがき
ということで、紙面に載せられなかった「技術的な話」はこれでおわりです。
技術的な「細部」をご紹介しました。紙面では、担当の方に無理を言って「Grad-CAM」の名称だけは入れて下さい…!とお願いしました。手法を書かないと、それが「主観的な感想」なのかどうか分からないからです。
それ以外の部分も、出力された図や出典を盛り込みたかったのですが、限られたスペース(1ページ)をいかに読者目線で使うか、というのが担当された編集者様からビンビン伝わってきて、本当に頭の下がる思いでした。この場を借りて、お礼申し上げます。
最後までお読みいただいた方、ありがとうございました。よかったら書店で手にとって見てくださいね。

