本人拒否率(本人棄却率)と他人受入率、等価エラー率の測定

より詳細な学習モデルの検証記事を出しております。
・日本人顔認識のための新たな学習モデルを作成 ~ EfficientNetV2ファインチューニング ~
・複数の学習済みモデルを評価する。評価項目と各コードを紹介。
上記記事では日本人専用のAI学習モデル「JAPANESE FACE」とDlibの汎用学習モデル(dlib_face_recognition_resnet_model_v1.dat)の性能比較や、以下の一般的な評価指標とその検証コードについて書かれています。
- AUC-ROC (Area Under the Curve – Receiver Operating Characteristic)曲線
- 精度(Accuracy)
- F1スコア (F1 Score)
- 混同行列(Confusion Matrix)
- 適合率(Precision)
- 再現率(Recall)
- モデルの解釈可能性 (Model Interpretability)
【本人拒否率と他人受入率について】の続編として Face01 の 汎用学習モデル(dlib_face_recognition_resnet_model_v1.dat)について、FRR ( 本人拒否率・本人棄却率 ) , FAR ( 他人受入率 ) , EER ( 等価エラー率 ) それぞれの測定を行います。
測定方法は2種類を用意しました。
- in Vivo
測定対象顔画像ファイルに対して鏡像ファイルを作り、測定対象顔画像ファイルとの顔距離を測定する - in Wild
測定対象顔画像ファイルに対してインターネットからランダムに対象者の写真をダウンロードし、測定対象顔画像ファイルとの顔距離を測定する
上記2種類の検証結果を元にそれぞれに於いて FAR, FRR, EER を計算します。
今回の記事では「in Vivo」での精度検証を扱います。
相関関係図
はじめに【本人拒否率と他人受入率について】のおさらいをします。
顔認証に限らず生体認証には本人拒否(棄却)率(FRR: False Reject Rate)と他人受入率(FAR: False accept Rate)の 2 つが存在します。
- 本人拒否率 ( FRR ):本人の生体情報と照合したときに本人が拒否される率で、値が低いほど認証精度が高い
- 他人受入率 ( FAR ):他人の生体情報と照合したときに受け入れられてしまう率を表し、値が小さいほど認証精度は高い
- 等価エラー率 ( EER ) : FRR と FAR が等しくなる時の率。値が小さいほど認証精度は高い
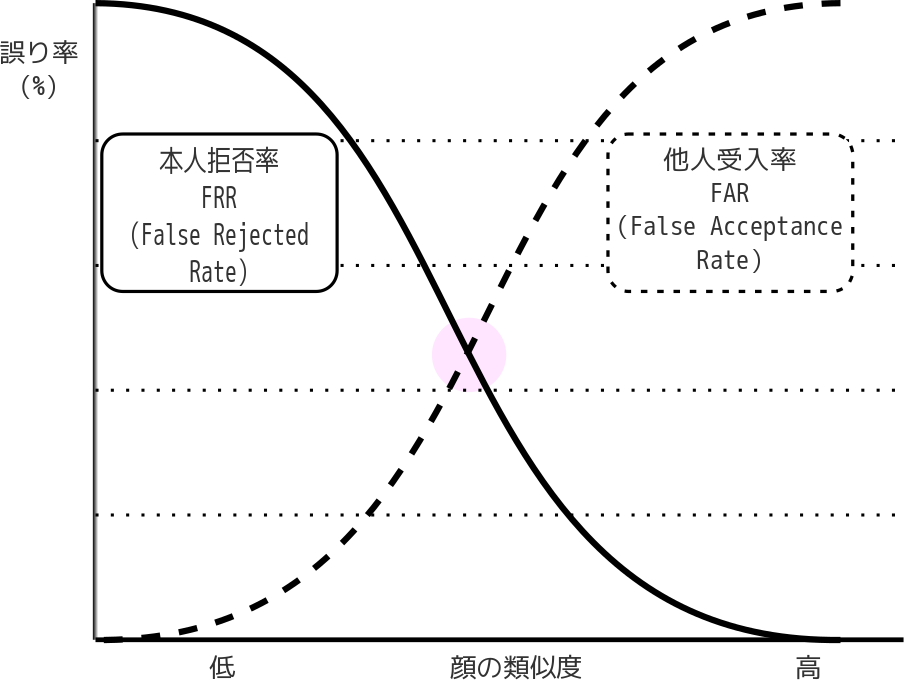
図1 では本人拒否率と他人受入率の相関関係をグラフで表しています。これらの数値は相関関係にあるため、どの値で閾値を設けるかによって変動します。中央のピンク色の丸が最もバランスのとれている閾値の値です。
このピンク色の丸の位置が低ければ低いほど「顔認証としての精度が高い」と言う事が出来ます。
in Vivo 検証
顔認証に求められる精度は、理想的な環境下における 1:1 照合での認証精度として他人受入率 ( FAR ) 0.01% の時に本人拒否率 ( FRR ) 0.15% 以下の性能は満たしているかどうかがある種の基準となっています。
テスト環境では「理想的な環境下」を作りにくいので、しばしば鏡像ファイル(ミラーリング画像)が用いられます。「in Vivo 検証」では、元の顔画像ファイルから鏡像(ミラーリング)を用意します。


各 1102 人分の顔画像ファイルについて 1:1 認証を行います。
本人ペアにおける 1:1 認証
本人同士、つまり元の顔画像ファイルとミラーリングした顔画像ファイルについて 1:1 認証を行います。
# coding: utf-8
import face_recognition
import cv2
import numpy as np
import os
import glob
base_dir = "/home/terms/ビデオ/PASONICA_JPN用/"
# それぞれのフォルダのファイルから配列を作成する ==========================
os.chdir(base_dir + "整頓してないクロップ済みの芸能人顔写真/")
img_files = glob.glob("*")
os.chdir(base_dir + "整頓してないクロップ済みの芸能人顔写真_mirror/")
mirror_files = glob.glob("*")
# ======================================================================
distances = []
for mirror_file in mirror_files:
for img_file in img_files:
if img_file + '_mirror.jpg' in mirror_file:
# img_file についてエンコーディングをする
try:
loaded_img_file = face_recognition.load_image_file(base_dir + "整頓してないクロップ済みの芸能人顔写真/" + img_file)
loaded_img_file_face_location = face_recognition.face_locations(loaded_img_file, number_of_times_to_upsample=0, model='cnn')
img_file_encoding = face_recognition.face_encodings(loaded_img_file, loaded_img_file_face_location, num_jitters=0, model='large')
array = [img_file_encoding[0], img_file_encoding[0]]
except:
print('_42', img_file, 'の読み込みに失敗しました')
continue
try:
loaded_mirror_file = face_recognition.load_image_file(mirror_file) # PIL で読み込んで numpy 配列を返す
loaded_mirror_file_face_location = face_recognition.face_locations(loaded_mirror_file, number_of_times_to_upsample=0, model='cnn')
mirror_file_encoding = face_recognition.face_encodings(loaded_mirror_file, loaded_mirror_file_face_location, num_jitters=0, model='large')
face_distances = face_recognition.face_distance(array, mirror_file_encoding[0])
except:
print('_50', mirror_file, 'の読み込みに失敗しました', )
continue
distances.append(face_distances[0])
try:
with open(base_dir + '本人拒否率_数値_in_vivo.csv', mode='w') as f:
f.writelines([str(n)+',\n' for n in distances])
except:
print('_61 人拒否率_数値_in_vivo.csvの書き込みに失敗しました')他人ペアにおける 1:1 認証
全ての人物における組み合わせを作り、各々の顔距離を測定します。
# coding: utf-8
import face_recognition
import cv2
import numpy as np
import os
import itertools
import glob
import re
import pickle
base_dir = "/home/terms/ビデオ/PASONICA_JPN用/"
# numpyのプリントオプション
np.set_printoptions(suppress=True, precision=30)
# それぞれのフォルダのファイルから配列を作成する ==========================
os.chdir(base_dir + "test/")
img_files = glob.glob("./**/*.jpg")
# ======================================================================
distances = []
pair = {}
kumiawase = []
count = 0
count_1 = 0
for img_file in img_files:
try:
loaded_img_file = face_recognition.load_image_file(img_file)
loaded_img_file_face_location = face_recognition.face_locations(loaded_img_file, number_of_times_to_upsample=0, model='cnn')
img_file_encoding = face_recognition.face_encodings(loaded_img_file, loaded_img_file_face_location, num_jitters=0, model='large')
except:
print('_39 img_file is', img_file); continue
# ファイル名とエンコーディング値の辞書オブジェクトを作成する
pair[img_file] = img_file_encoding
count += 1
print('_37', count,'/',len(img_files), ' ', round(count / len(img_files) * 100), '%')
with open(base_dir + '個人顔距離辞書ファイル.dat', mode='wb') as f:
pickle.dump(pair, f)
pattern = '^\.\/(.*)\/.*'
array = []
for i,n in itertools.combinations(pair, 2):
count_1 += 1
result = re.match(pattern, i)
name = result.group(1)
if name in n:
print('_97', name, 'がかぶります', i, n)
print('_98', '処理を飛ばします')
continue
else:
print('_92', 'i: ', i, ' ', 'n: ', n)
print('_194 顔距離を測定します')
array = [pair[i][0], pair[i][0]]
face_distances = face_recognition.face_distance(array, pair[n][0])
distances.append(face_distances[0])
with open(base_dir + '他人ペア顔距離測定結果_その2.csv', mode='w') as f:
f.writelines([str(n)+',\n' for n in distances])
print('_112 終了しました')出力数値とその加工方法
実際にそれぞれのコードで出力される数値は各人物間の顔距離 ( Face distance ) がカンマ区切りになった CSV 形式のファイルです。
0.06398155706092067,
0.10088957904484053,
0.0892964012139987,
0.07742239783814651,
0.0883897129058168,
0.10929197918415638,
0.06844336088654676,
0.09585399079438936,
....その数は本人ペアの場合 1100 程度、他人ペアの場合 648,000 以上になります。
これらを表計算ソフトに入力、その後 FFR, FAR, EER を求めつつグラフ化をします。
顔距離は小数点以下 17 桁ですが、これを小数点第4位、第3位…と丸めます。こうすることで正確性をある程度保ったまま膨大な計算量を減らします。
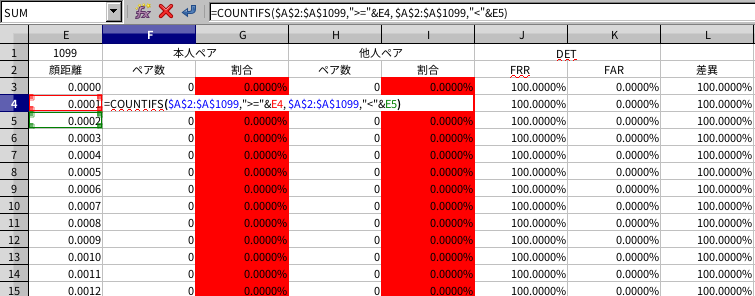
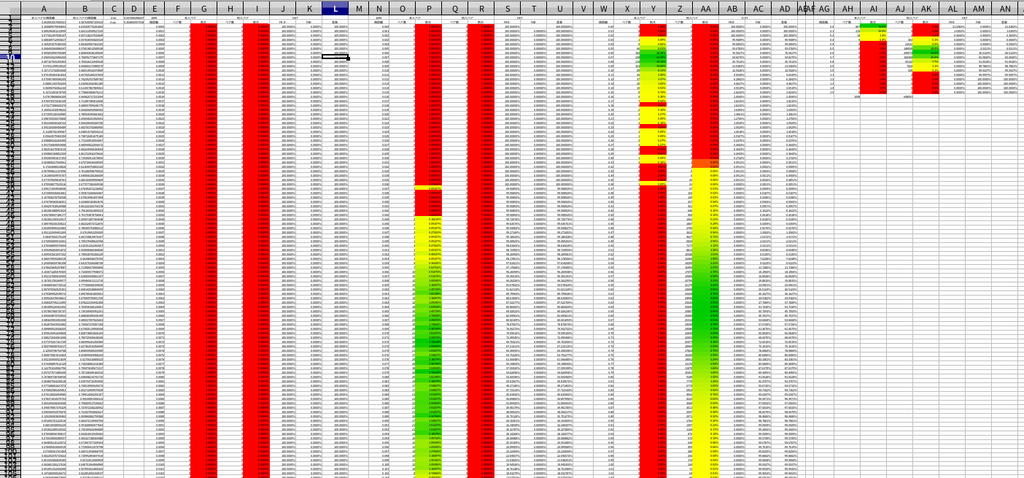
検証結果
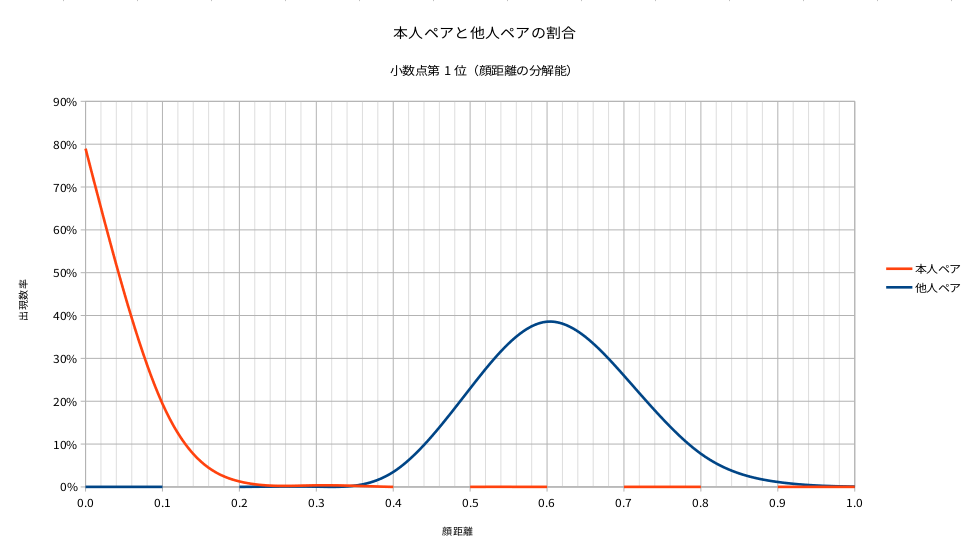
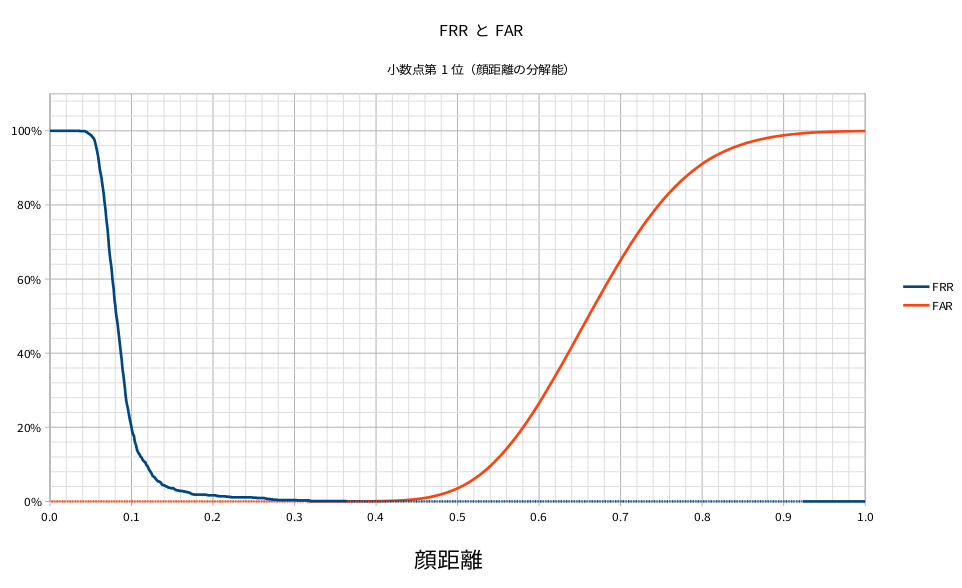
上のグラフは冒頭にお見せした下のグラフになります。交差ポイントが非常に低い値になっていることがお分かりいただけると思います。
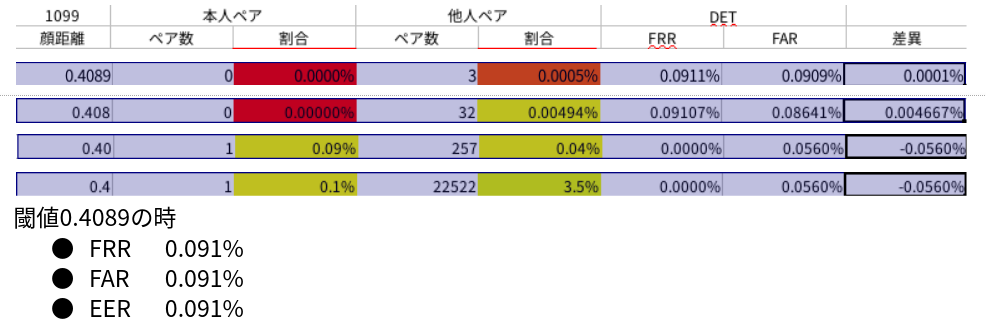
EER ( Equal error rate: 等価エラー率 ) は FAR と FRR が等しい時の数値です。小数点第4位での数値では 0.091% となりました。これは閾値を 0.4089 とした時の 1000 回顔認証にて、本人を他人と間違える確率 ( FRR ) が 1 回未満、他人を本人と間違える確率 ( FAR ) も 1 回未満となることを意味します。

FAR が 0.01% の時の FRR は 0.00% 未満であることが分かりました。
まとめ
【理想的光源下】という場合は通常正面顔であることも含まれますが、今回の検証では斜め顔も含まれています。この場合、全ての写真が「積極認証とはいえない」となり、通常は EER 値が上がってしまいます。この様な条件下で EER = 0.091% であり、更に「FAR が 0.01% の時の FRR は 0.00% 未満」であることから、少人数を対象とした顔認証システムを構築する場合は性能が非常によい、と言えます。
実際の顔認証では様々な悪条件が重なるため、理論値通りの認証率にはならないものです。次回はその様な悪条件、「in Wild」を測定・検証してみたいと思います。
以上です。
最後までお読み頂きありがとうございました。
より詳細な学習モデルの検証記事を出しております。
・日本人顔認識のための新たな学習モデルを作成 ~ EfficientNetV2ファインチューニング ~
・複数の学習済みモデルを評価する。評価項目と各コードを紹介。
上記記事では日本人専用のAI学習モデル「JAPANESE FACE」とDlibの汎用学習モデル(dlib_face_recognition_resnet_model_v1.dat)の性能比較や、以下の一般的な評価指標とその検証コードについて書かれています。
- AUC-ROC (Area Under the Curve – Receiver Operating Characteristic)曲線
- 精度(Accuracy)
- F1スコア (F1 Score)
- 混同行列(Confusion Matrix)
- 適合率(Precision)
- 再現率(Recall)
- モデルの解釈可能性 (Model Interpretability)